

Que sont les traces ?
Définition des traces distribuées
Les traces distribuées constituent une forme de données télémétriques qui offrent un enregistrement de bout-en-bout, au niveau du code (transaction), de chaque requête utilisateur sur l'ensemble du chemin parcouru par une application.
Le traçage distribué permet de visualiser l'état de santé d'une application, ses dépendances et les interactions entre les différents composants du système. C’est un élément essentiel de l’ observabilité et du suivi des performances applicatives (APM) dans les environnements natifs du cloud.
Les traces permettent aux équipes d'ingénieurs de fiabilité des sites (SRE), ITOps et DevOps de comprendre le cheminement et le comportement complet des requêtes à travers les différents microservices au sein d'un système. En utilisant les traces, les développeurs ont la possibilité de repérer les points de blocage et autres soucis de code qui nuisent à la performance et à l'expérience utilisateur, et de les optimiser pour améliorer l'efficacité.
Traçage distribué vs. traçage traditionnel
Le traçage distribué consiste à observer les requêtes à mesure qu'elles transitent par des environnements distribués.
Par nature, une architecture distribuée comprend un ensemble complexe de services. Une requête parcourt une multitude de microservices, chacun réalisant une tâche particulière. Par conséquent, le traçage d'une requête dans un système distribué représente une tâche complexe qui s'avérerait irréalisable avec le traçage classique employé pour les applications monolithiques.
Le traçage traditionnel fournit des informations limitées et n’est pas scalable. L'approche de traçage traditionnelle emploie des échantillons aléatoires de traces issues de chaque requête, ce qui produit des traces incomplètes.
Pourquoi le traçage est-il important pour le développement d'applications ?
Le traçage est essentiel au développement applicatif car il offre aux ingénieurs logiciels la possibilité de suivre une requête à travers une multitude de microservices. Le fait de pouvoir suivre visuellement chaque étape confère au traçage une valeur inestimable. Cela permet de corriger les anomalies et les problèmes de performance en diagnostiquant les erreurs pour différentes applications.
Le traçage permet de :
- Détecter les problèmes plus rapidement : dans un système distribué, la recherche de pannes est bien plus ardue que dans un monolithe. Grâce au traçage distribué, il est possible de déterminer rapidement la cause première et l'endroit des erreurs d'application, ce qui minimise les interruptions.
- Simplifier le débogage : le traçage fournit une vision complète de l'interaction des requêtes avec les divers microservices, ce qui aide au processus de débogage, y compris dans les architectures les plus complexes.
- Améliorer la collaboration : Au sein d'un environnement distribué, il est fréquent que diverses équipes interviennent sur des services différents. Une trace permet de localiser l'origine du problème et indique l'équipe chargée de le corriger.
- Accélérer le développement : le traçage permet aux développeurs d'acquérir des connaissances importantes sur le comportement utilisateur, d'optimiser la performance applicative et de simplifier les efforts de publication de mises à jour et de nouveaux déploiements.
Fonctionnement du traçage
Le traçage s'effectue en recueillant, en analysant et en visualisant les données de télémétrie d'une requête au fur et à mesure qu'elle transite par divers services dans une architecture de microservices.
Pour que les données de traçage (et autres données de télémétrie) soient produites, il est nécessaire d'instrumenter une application au préalable. L'instrumentation est un processus qui consiste à ajouter du code pour suivre les données de traçage. Une plateforme open source comme OpenTelemetry (OTel) fournit des SDK, API et autres outils indépendants de tout fournisseur pour l'instrumentation d'une architecture de microservices.
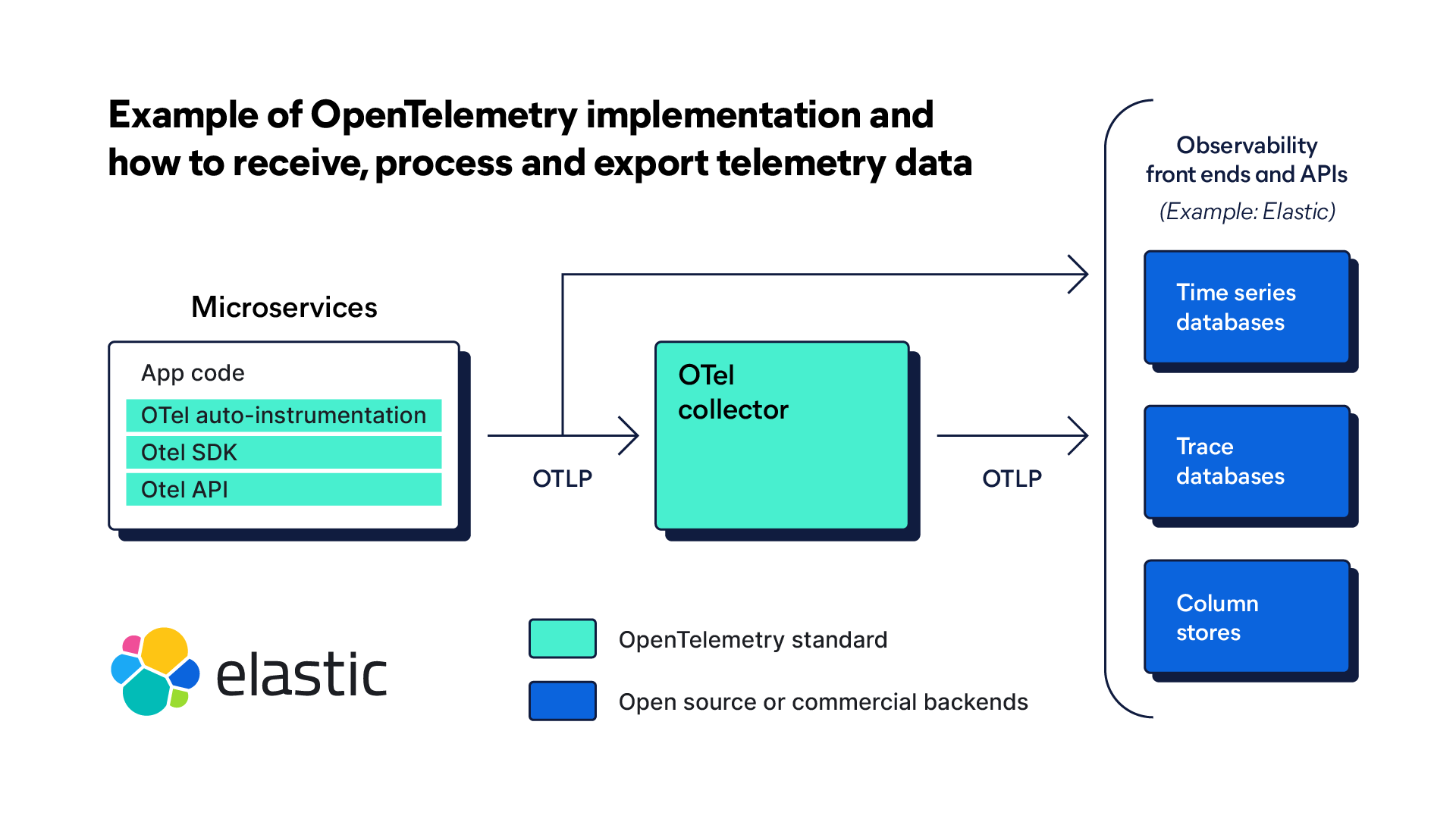
Collecte de données
Un outil de traçage distribué de bout-en-bout se met à recueillir des données dès qu'un utilisateur lance une requête. Des informations d'identification, soit l'identifiant de trace, sont ajoutées à chaque requête au moment où elle entre dans le système. Ces informations d'identification sont transmises au fur et à mesure de leur passage à travers divers services et composants.
Chaque étape du parcours de la requête est également enregistrée. L'étendue initiale est nommée l'étendue mère, et chaque étendue suivante est une étendue fille. Chaque étendue fille est codée avec l'ID de trace d'origine, un ID d'étendue distinct, un timestamp, un état et d'autres métadonnées importantes. Une organisation hiérarchique structure les étendues, qui suivent le cheminement des services dans tout l'environnement.
Dans le cadre de l'APM, instrumenter une application et activer la collecte de traces rendent possible la collecte de métriques de traçage applicatif, soit des valeurs numériques, qui peuvent servir à suivre la performance de l'application. Celles-ci incluent :
- Taux de requête — le nombre de requêtes par seconde
- Taux d'erreur — le nombre de requêtes qui échouent
- Latence — le temps nécessaire pour répondre à une requête
- Durée — le temps que prend la requête
- Débit — le volume de requêtes qu'une application peut traiter dans un laps de temps donné
Analyse des traces
Après l'exécution de la requête et la collecte de toutes les données par la trace, les données sont regroupées. En se servant des données issues des étendues, comme les identifiants de trace, les horodatages et d'autres informations contextuelles, les développeurs ont la possibilité de repérer les blocages de ressources, les problèmes de latence ou les erreurs.
Suivi et visualisation
Le suivi des métriques d’une application peut aider à monitorer les performances. Le cas échéant, et au moment où elles évoluent, les équipes SRE et DevOps peuvent se mettre en action sans délai.
Grâce à l'intelligence artificielle (IA) ou machine learning, la procédure de suivi peut être automatisée en partie et les ingénieurs reçoivent des alertes concernant des problèmes potentiels avant qu'ils ne se produisent. Grâce à un assistant d'IA, il est également possible d'analyser les traces plus en détail et d'explorer rapidement les problèmes fondamentaux en mettant en relation les données d'observabilité d'autres origines.
Pour finir, l'ensemble des étendues est représenté dans un graphique de type cascade, l'étendue mère figurant au sommet et les étendues filles imbriquées en dessous. Ce graphique présente une vision panoramique de l'activité d'une application pendant sa tentative de réponse à une requête. De cette manière, les ingénieurs sont en mesure d'identifier les sections d'un système distribué qui subissent des problèmes de performance, des erreurs ou des blocages.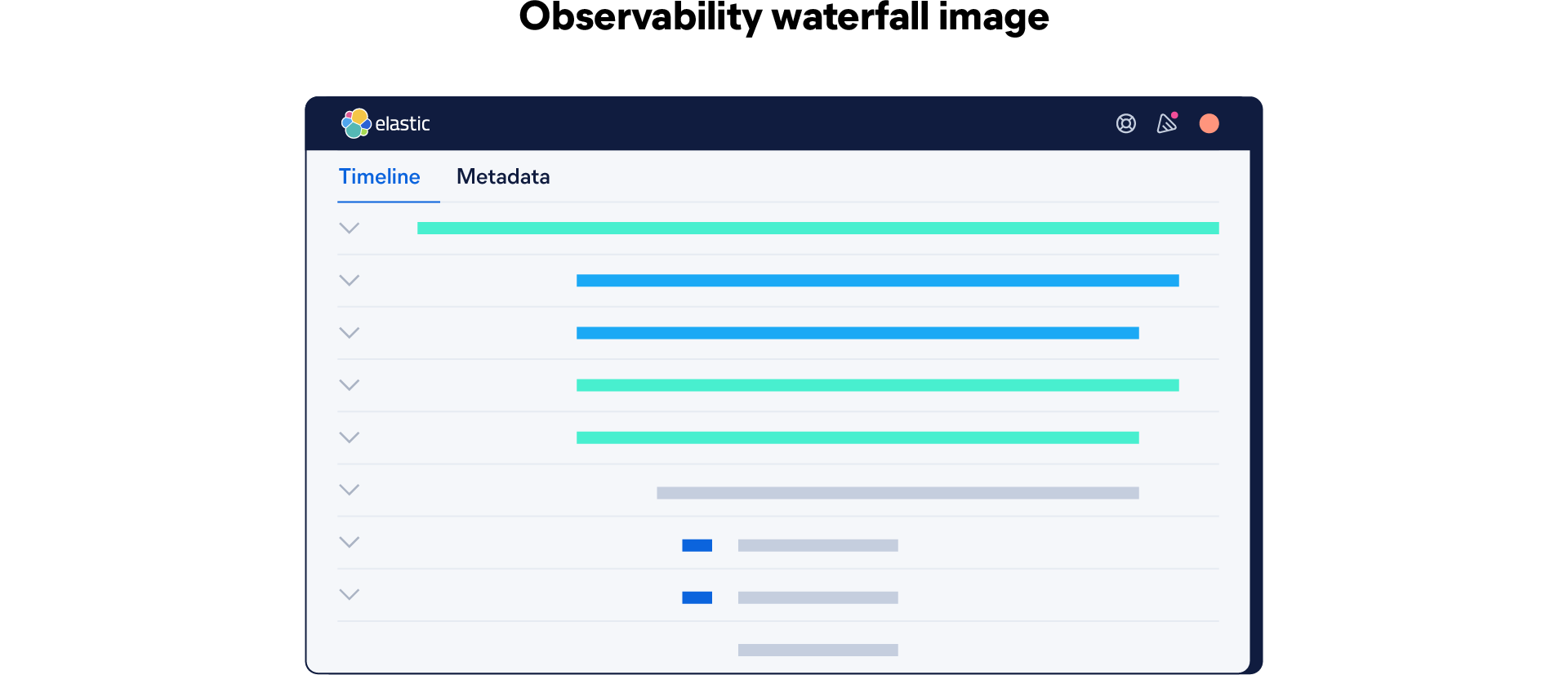
Normes ouvertes pour le traçage dans OpenTelemetry
OpenTelemetry est un framework d'observabilité open source composé d'outils, d'API et de SDK. OTel donne la possibilité aux équipes SRE, DevOps et IT d'instrumenter, de recueillir et d'exporter les données télémétriques — incluant les traces — dans un format seul et unifié pour l'analyse.
La Cloud Native Computing Foundation (CNCF) a conçu OTel pour offrir des protocoles, des schémas et des outils standardisés permettant la collecte et l'acheminement des données télémétriques vers les plateformes d'observabilité. Fortement axé sur les traces, OTel est le résultat d'une fusion de deux projets CNCF antérieurs : OpenTracing et OpenCensus. Leur conception visait à établir une norme unique pour l'instrumentation du code et le routage des données de télémétrie vers une infrastructure d'observabilité.
Depuis 2019, moment du regroupement des deux projets, les communautés open source et les entreprises ont recours à OTel car il propose un format d'instrumentation unique et unifié et qu'il est conçu pour l'avenir.
Avant OpenTelemetry et ses standards ouverts, les données d'observabilité étaient souvent incohérentes et difficiles à corréler. Au sein d'un environnement distribué, les équipes DevOps et IT étaient tenues d'instrumenter différentes bibliothèques compatibles avec les multiples applications et services de leur entreprise, et ce, à travers divers langages de programmation. Bien souvent, chaque outil d'instrumentation de code, d'APM ou de traçage était spécifique à un fournisseur, ce qui posait d'innombrables problèmes pour le traçage distribué. En l'absence de standard et d'outil unique pour recueillir (et exporter) les traces de toutes les applications, le travail des ingénieurs visant à identifier les problèmes de performance ou les erreurs se transforme en défi.
Grâce à OTel, d'un autre côté, les ingénieurs n'ont pas besoin de réinstrumenter le code pour suivre les données de trace de divers services, et ils n'ont pas non plus à réacheminer manuellement les données de télémétrie à chaque changement. Un unique framework open source existe pour les outils d'observabilité et de surveillance qui respectent la norme OpenTelemetry.
Avec l'arrivée de nouvelles technologies — comme des intégrations plus profondes avec l'IA pour la détection d'anomalies et l'IA générative —, OpenTelemetry continuera d'offrir un cadre d'intégration unique et supporté pour le traçage distribué intégral.
Les standards OTel en matière de traçage incluent :
- Un ensemble unique d'API et de conventions pour la collecte des données de traçage
- L'étendue est définie comme une unité fondamentale du traçage
- Des conventions sémantiques pour la dénomination des étendues et l'ajout d'attributs
- Un mécanisme de contexte permettant de relier les étendues entre différents services
- Compatibilité avec différents langages de programmation
En savoir plus sur OpenTelemetry avec Elastic
Traces, indicateurs, logs et profils
Les données de télémétrie — logs, métriques et traces — offrent une observabilité complète du comportement des applications, serveurs, services ou bases de données dans un environnement distribué. Connus également sous le nom des trois piliers de l'observabilité, les logs, les métriques et les traces forment un enregistrement complet et mis en corrélation de chaque requête et transaction utilisateur.
Les trois types de données fournissent chacun des informations cruciales sur l'environnement. Conjointement, ils permettent aux équipes DevOps, IT et SRE de suivre la performance de l'intégralité du système en temps réel et sur la durée.
Traces
Les traces sont des enregistrements détaillés du parcours d'une requête à travers l'ensemble du système distribué afin de fournir du contexte. En centralisant des données cloisonnées et en consignant chaque action d'un utilisateur, les traces aident les ingénieurs à identifier les points de blocage, à déboguer et à monitorer les applications qui exploitent plusieurs applications, et à comprendre les dépendances et les interactions entre les composants du système.
Logs
Les fichiers de log sont les enregistrements horodatés des événements et des messages système. Généralement, les logs sont utilisés pour le dépannage et le débogage. Ils offrent un éclairage sur le fonctionnement du système et aident à repérer les anomalies.
Qui plus est, la majorité des langages de programmation disposent de capacités de logging intégrées. Par conséquent, les développeurs ont l'habitude de poursuivre l'utilisation de leurs frameworks de logging actuels.
En savoir plus sur le logging et OpenTelemetry
Indicateurs
Les métriques sont des valeurs numériques qui représentent l'état ou la performance d'un système sur une période donnée. Les métriques sont les principaux indicateurs de performance. Les équipes DevOps et d'autres les emploient afin de suivre l'état de santé du système, de repérer les tendances et de déclencher des alertes.
Profils : le futur quatrième pilier de l’observabilité moderne
Les métriques, les logs et les traces offrent des informations précieuses sur ce qui se passe et où. Il est essentiel de comprendre également les raisons du comportement du système : quelle est la cause d'un goulet d'étranglement de la performance ou d'un calcul inefficace ? C'est précisément le rôle du profilage continu. Il contribue à une vision globale du système, en offrant un niveau de visibilité plus poussé — jusqu'au code source.
En savoir plus sur les piliers de l'observabilité
Comment mettre en œuvre le traçage distribué
Les traces distribuées sont essentielles pour le suivi et le dépannage des systèmes complexes et des applications distribuées. Avant de mettre en œuvre le traçage distribué, il est important de définir les objectifs et les besoins en matière de traçage et d'identifier les services critiques et les chemins de requête. Voici cinq étapes pour une mise en œuvre réussie du traçage distribué :
- Sélectionnez un outil de traçage, comme OpenTelemetry (le framework qui fait maintenant référence pour la collecte des traces, des métriques et des logs). L'outil choisi devra être compatible avec votre pile technologique actuelle et pérenne.
- Instrumentez les services et les applications. Cela nécessite l'intégration de code de traçage dans votre base de code et la définition des traces (étendues) dans votre application.
- Collectez des traces en lançant une requête de collecte de données. Assurez-vous que les traces sont exactes et complètes grâce à la propagation contextuelle, un élément essentiel du traçage distribué.
- Exportez les traces à des fins de suivi, d'analyse et de visualisation vers le back-end de votre choix ou vers un fournisseur de services de traçage cloud.
- Identifiez les goulets d'étranglement, les inefficacités et les erreurs. Les données de traçage permettent de déceler les erreurs, de repérer les services aux performances lentes et de visualiser les flux de données à travers les services.
APM et traces distribuées avec Elastic
Le suivi des performances applicatives (APM) est un élément essentiel de l'observabilité moderne. Elle vous oriente à travers l'ensemble de vos données télémétriques en apportant du contexte et optimise l'analyse des causes racines grâce au machine learning.
Tirez parti d'Elastic Observability et de la puissance de la recherche pour améliorer la qualité du code grâce au traçage distribué de bout en bout. Capturez et analysez les transactions distribuées (microservices, architectures sans serveur et monolithiques), y compris la prise en charge d'AWS Lambda, de l'instrumentation automatique, mais aussi des langages populaires, comme Java, .NET, PHP, Python et Go. Réduisez les indisponibilités et optimisez l'expérience de la clientèle en annotant les transactions à l'aide des marqueurs de déploiement et des données sur les internautes.
Ressources concernant les traces
- [Blog] Comprendre les indicateurs d’observabilité : types, signaux clés et bonnes pratiques
- [Blog] Les 3 piliers de l'observabilité : logs, indicateurs et traces unifiés
- [Guide technique] Chronologie d'échantillon de trace
- [Guide technique] Traces