

Elasticsearch : recherche dans des bases de données et des systèmes d’entreprise
Aperçu
Présentation d'Elasticsearch
Elasticsearch met à votre disposition un éventail de techniques de recherche, à commencer par l'algorithme BM25, la norme du secteur pour la recherche textuelle. Il propose également une recherche sémantique alimentée par des modèles d’IA, améliorant les résultats en fonction du contexte et de l’intention.
Dans ce guide, vous apprendrez à synchroniser les données d'une base de données externe vers Elasticsearch et à utiliser la recherche sémantique pour effectuer facilement des recherches dans votre base de données.
Intégration de vos données
Comment ingérer et enrichir les données pour la recherche
Elasticsearch comprend un vaste éventail de fonctionnalités d'ingestion des données, qui vous aident à relever vos défis professionnels. Regardez ce webinar et :
- Apprenez à rassembler des données dispersées en un seul endroit afin de créer des expériences de recherche.
- Découvrez les outils à utiliser pour vos types de données spécifiques, notamment le robot d'indexation, le catalogue de connecteurs, les pipelines d’inférence de données et de ML, etc.
- Regardez les démonstrations en direct à l'aide d'ensembles de données du support technique client.
Créer un projet Elastic Cloud
Commencez un essai de 14 jours. Une fois que vous vous êtes rendu sur cloud.elastic.co et que vous avez créé un compte, procédez comme suit pour lancer votre premier projet Elasticsearch Serverless.
Pour commencer, sélectionnez Elasticsearch.
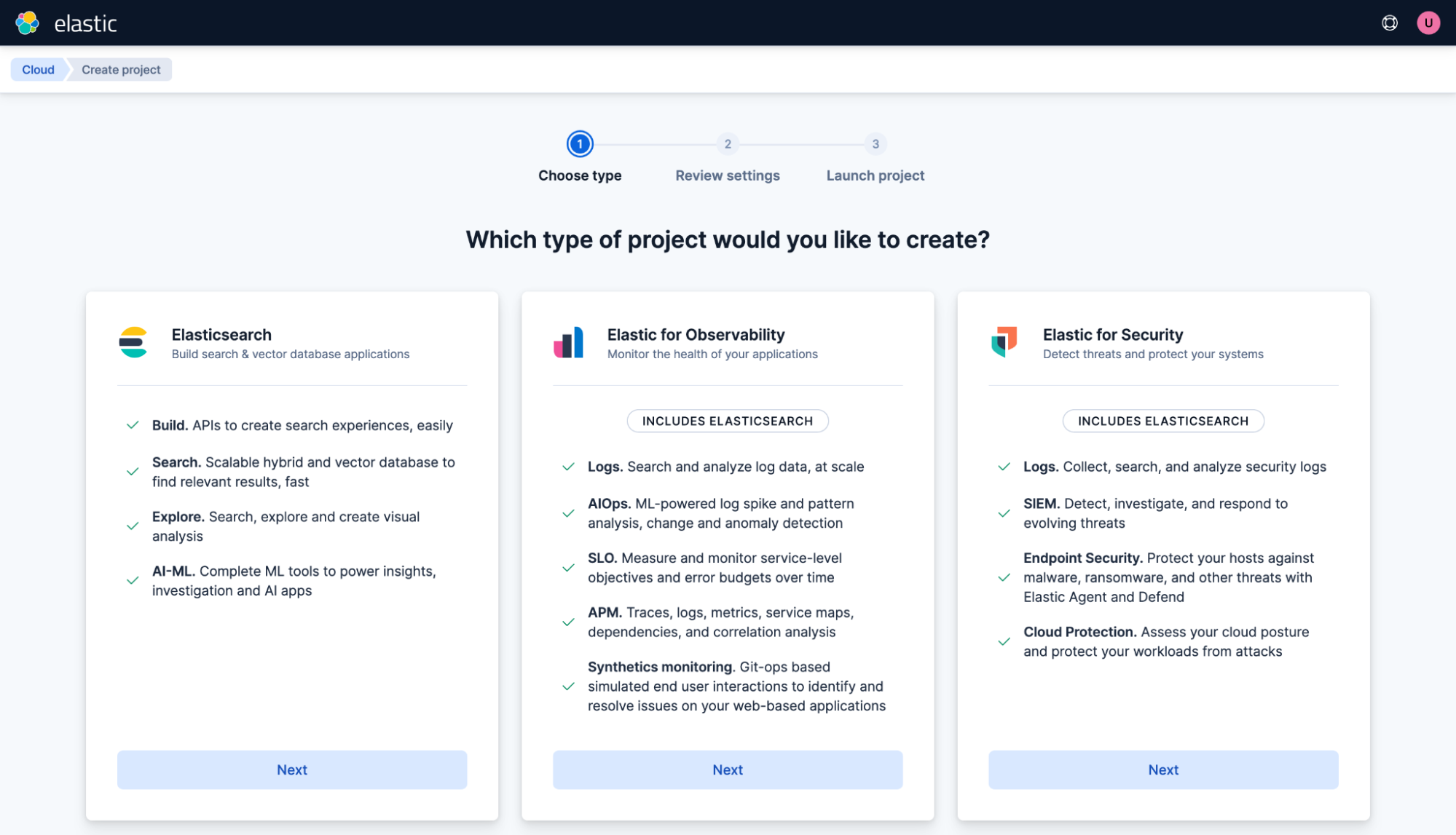
Créer un projet à usage général. Nommez-le « My project » et cliquez sur Créer un projet.
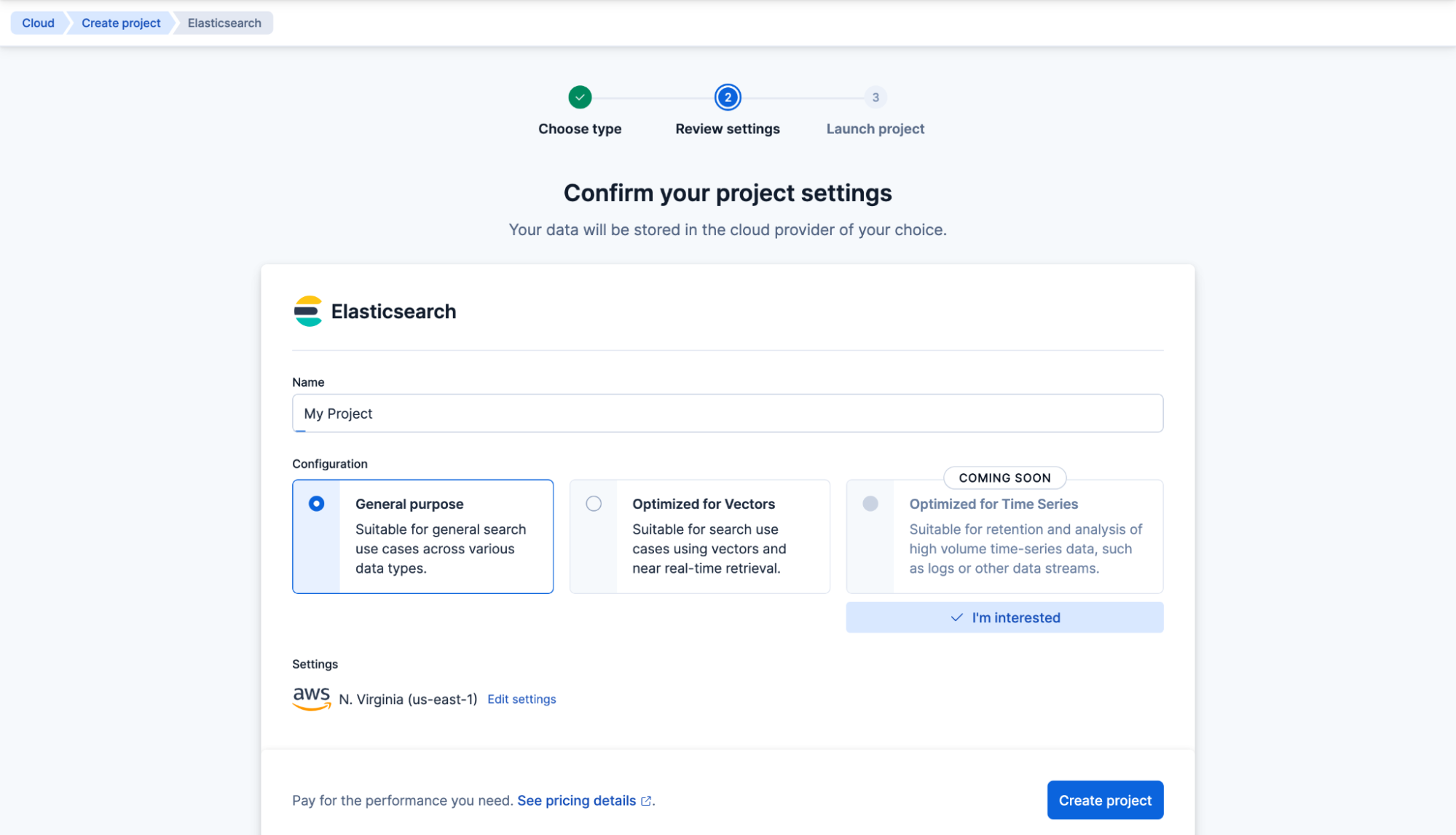
Votre projet Elasticsearch Serverless va maintenant être créé. Ensuite, créez votre premier index Elasticsearch et nommez-le « my-index ». Cliquez sur Créer mon index.
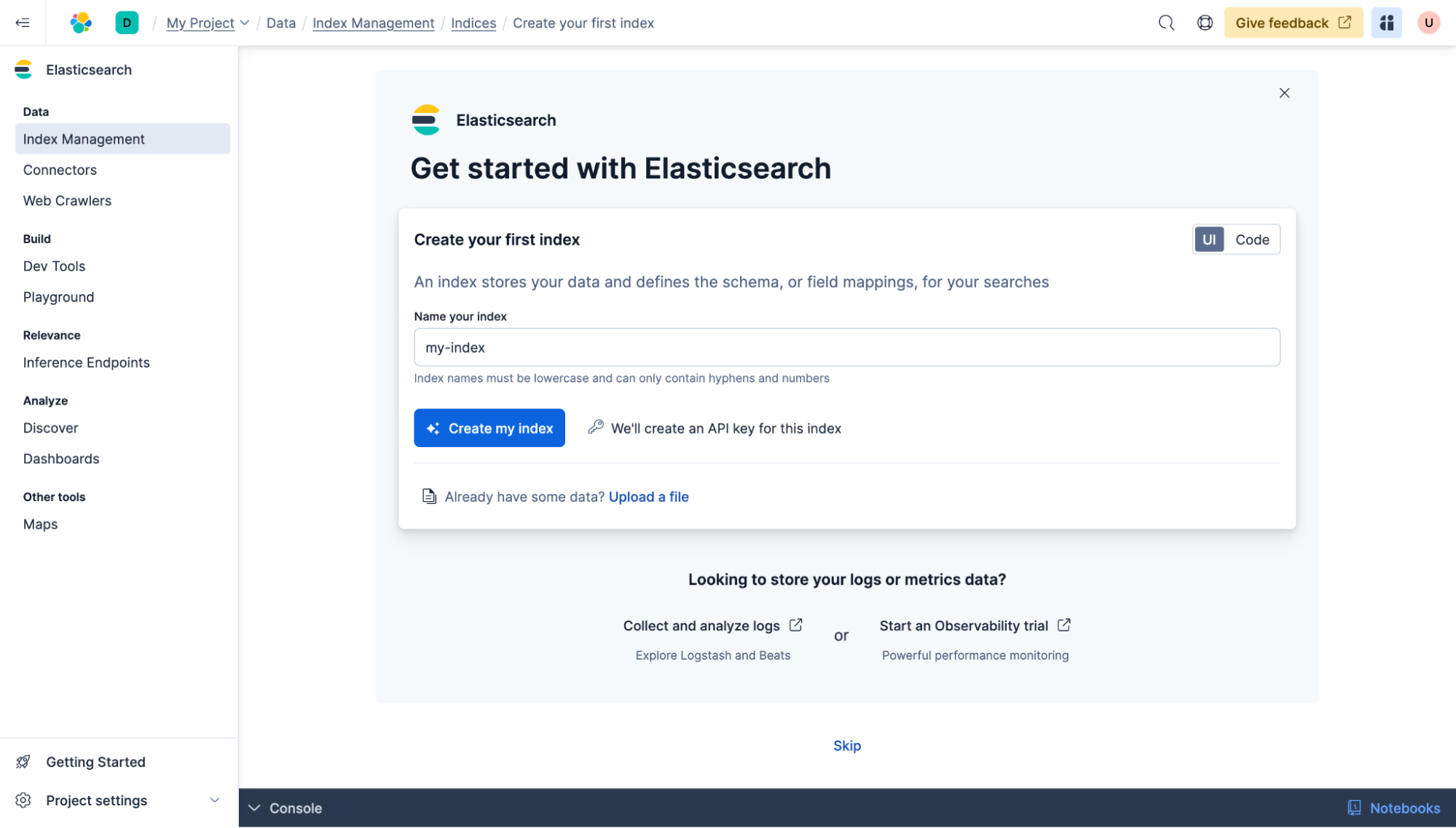
Ensuite, vous pouvez ajouter des sources de données tierces à Elasticsearch. Dans cet exemple, nous avons une base de données MongoDB contenant environ 150 000 titres de jeux vidéo et les colonnes "id", "name", "description'' et "date." Nous synchroniserons cette base de données avec Elasticsearch, et, comme étape supplémentaire, nous y ajouterons des capacités de recherche sémantique.
Créons un mapping d’index de base avec les mêmes noms de champs et le « description_semantic » supplémentaire qui contiendra nos vecteurs pour la recherche sémantique. Ouvrez les outils de développement et collez la commande suivante pour mettre à jour vos mappings :
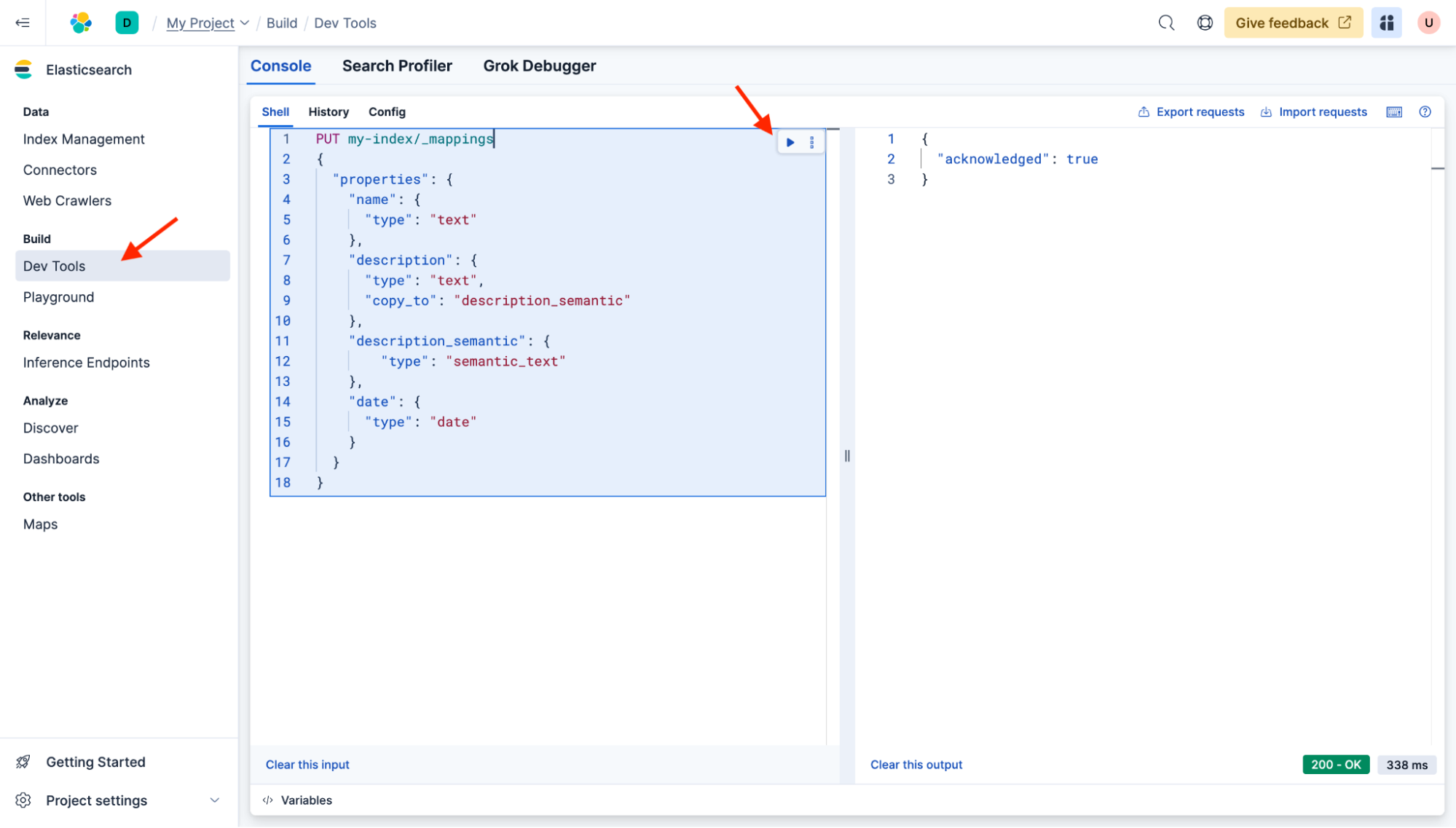
PUT my-index/_mappings
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"copy_to": "description_semantic"
},
"description_semantic": {
"type": "semantic_text"
},
"date": {
"type": "date"
}
}
}
Récupérer des données d'une base de données existante
Vous êtes prêt à vous connecter à une base de données existante. Cliquez sur Connecteurs et + Connecteur autogéré.
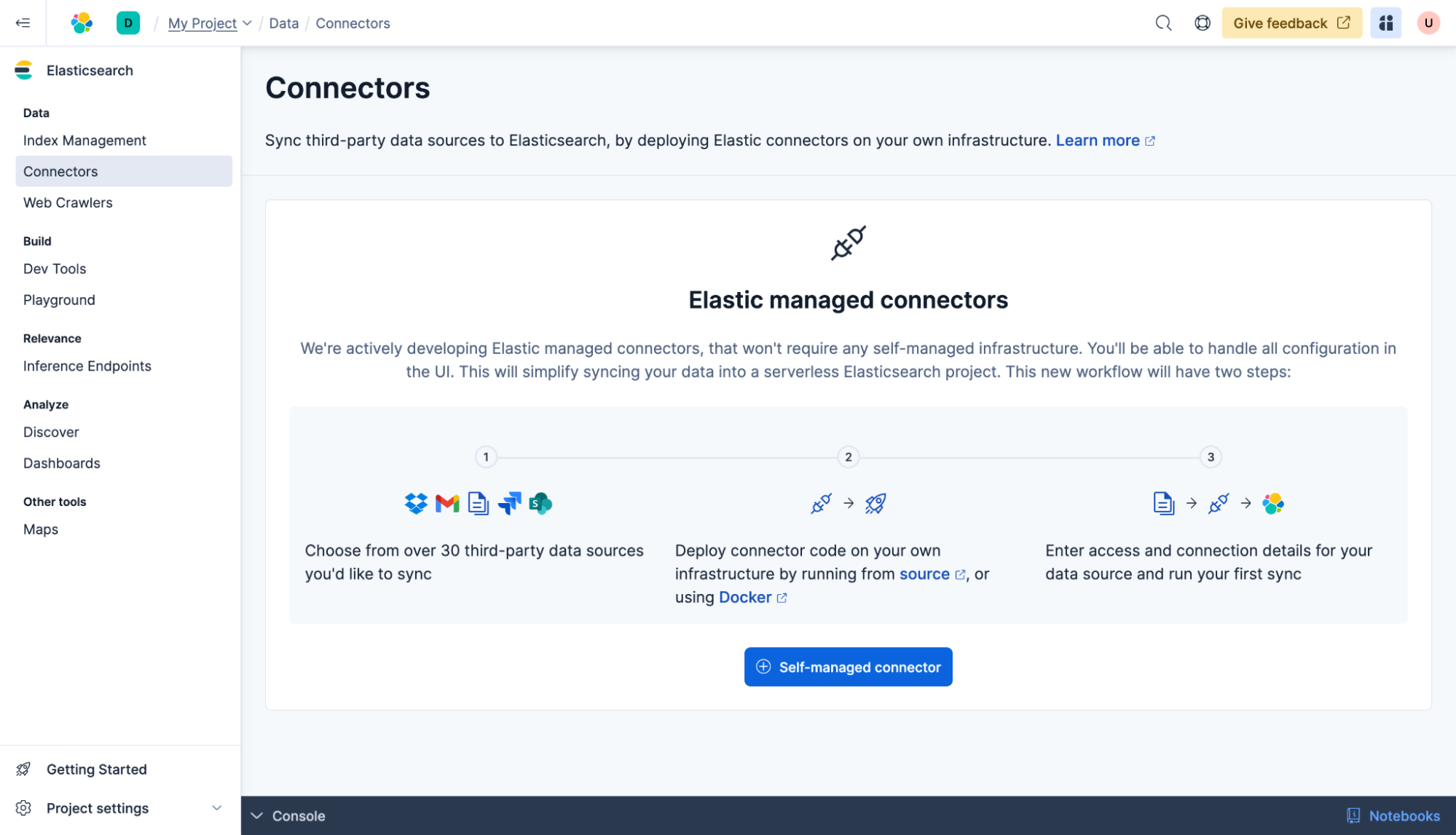
Ce guide utilisera une base de données MongoDB. Sélectionnez MongoDB dans la liste des types de connecteurs.
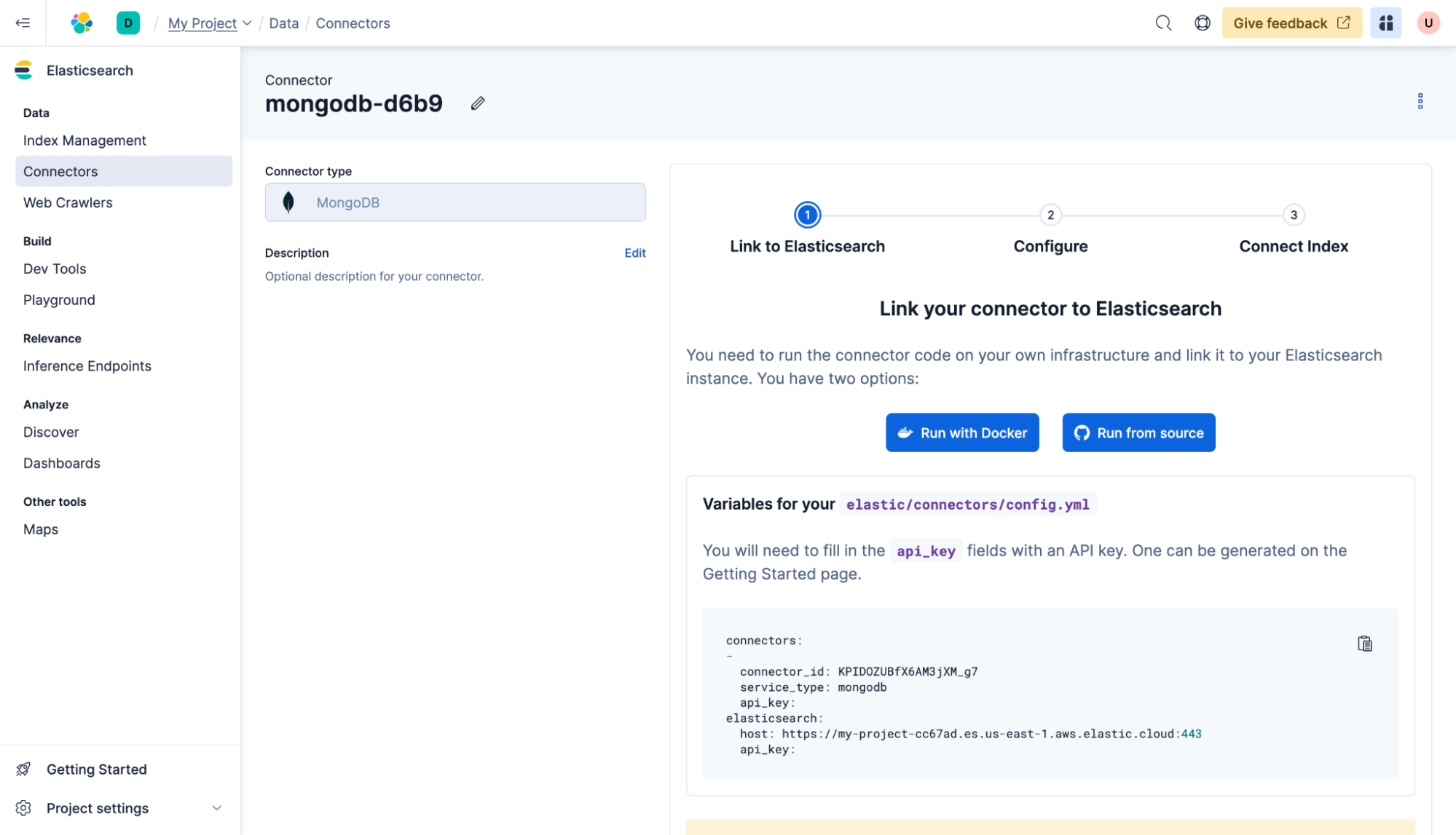
Suivez les instructions pour déployer un connecteur auto-hébergé à l’aide de Docker. Vous devrez créer un fichier config.yml. Gardez à l’esprit que l’api_key sur le connecteur et elasticsearch est le même. Par exemple :
Connecteurs :
-
connector_id : KPIDOZUBfX6AM3jXM_g7
service_type : mongodb
api_key : RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
elasticsearch :
hôte : https://my-project-cc67ad.es.us-east-1.aws.elastic.cloud:443
api_key : RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
Ensuite, démarrez le connecteur auto-hébergé en utilisant :
docker run -v "./connectors-config:/config" --tty --rm docker.elastic.co/enterprise-search/elastic-connectors:8.17.0 /application/bin/elastic-ingestion -c /config/config.yml
Ensuite, ajoutez la configuration à votre base de données MongoDB et cliquez sur Suivant.
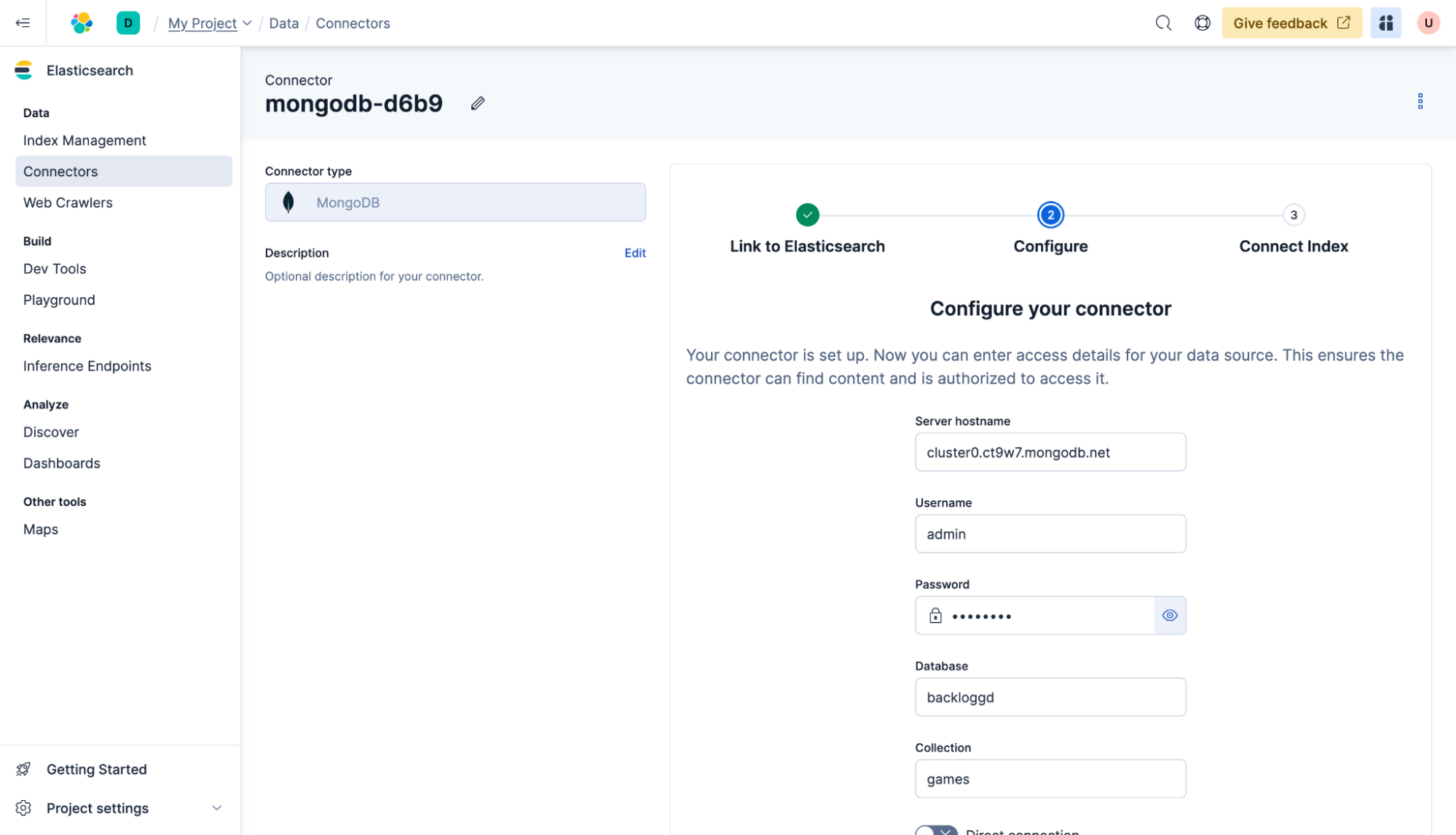
Sélectionnez l’index avec lequel les données doivent être synchronisées (dans ce cas, il s’agit de « my-index », l’index que nous avons créé auparavant). Cliquez sur Synchroniser.
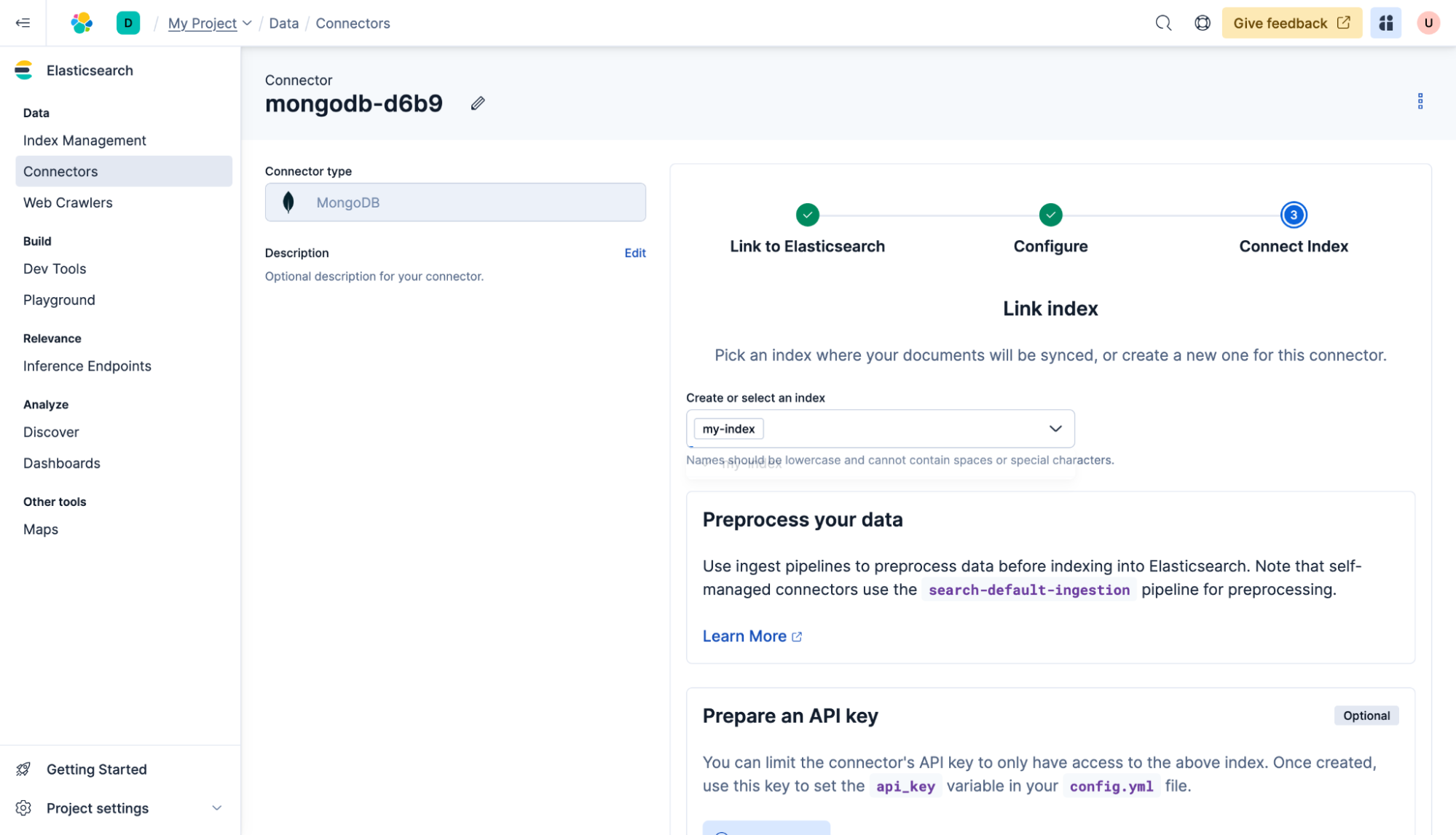
Voilà ! Le connecteur parcourra la base de données et synchronisera les documents avec « my-index ». La page principale des connecteurs indiquera l'état actuel.
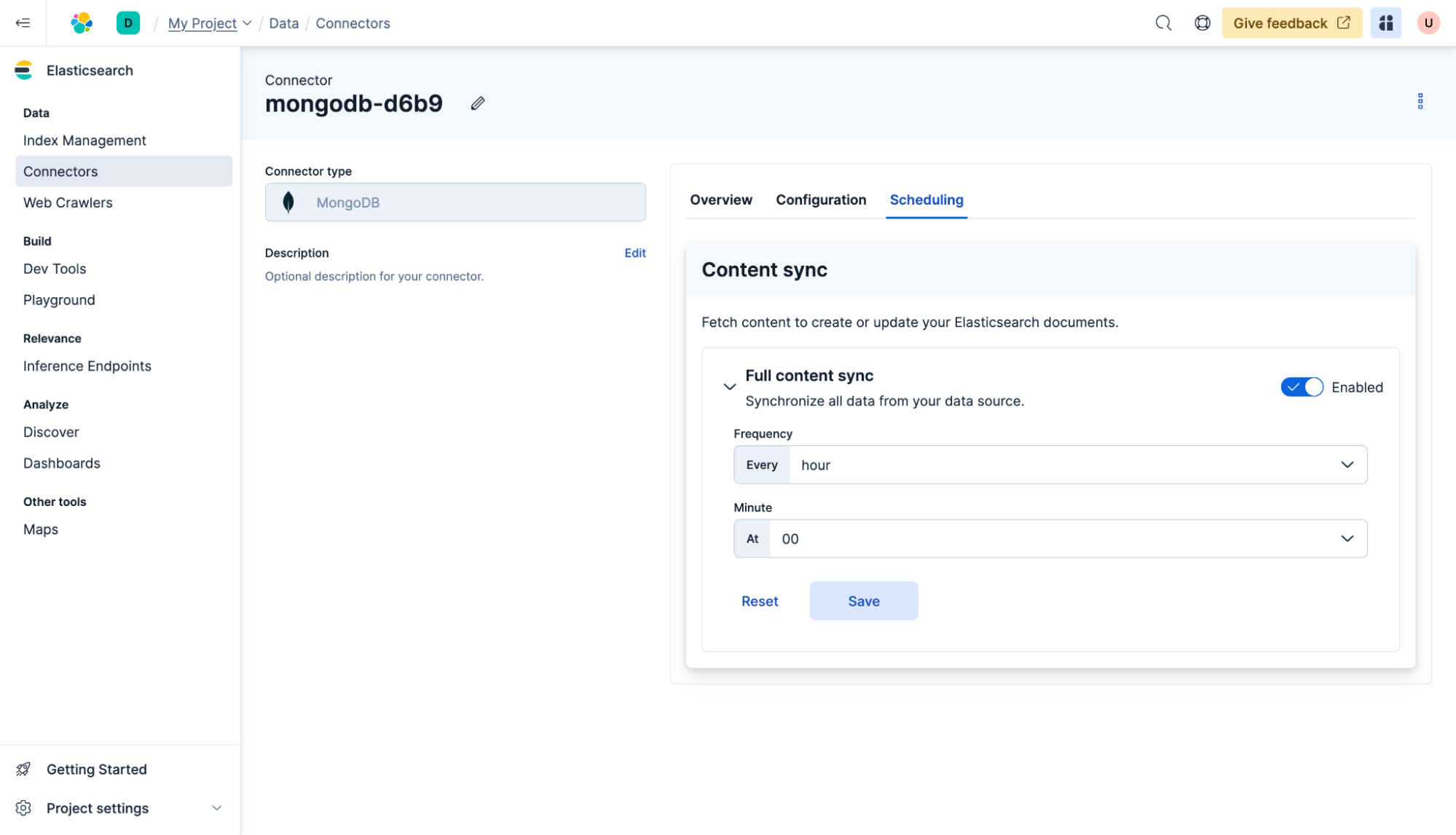
Les connecteurs peuvent également être configurés pour synchroniser régulièrement la base de données avec Elasticsearch. Pour ce faire, cliquez sur le connecteur, puis sur Planification, sélectionnez toutes les heures et cliquez sur Enregistrer. Désormais, le contenu sera synchronisé toutes les heures, à condition que le connecteur auto-hébergé soit opérationnel.
Fonctionnement d'Elasticsearch
Interrogation des données
C'est maintenant que la partie la plus amusante commence. Rendez-vous sur Build > Dev Tools (la même section que celle que nous avons utilisée pour mettre à jour les mappings des index) et lancez la requête suivante, qui effectuera une recherche full text dans les champs "name" et "description" :
GET my-index/_search
{
"query": {
"multi_match": {
"query": "adventure game on a desert island",
"fields": [
"name",
"description"
]
}
}
}
Puisque l'index a maintenant un champ semantic_text, vous pouvez l'interroger comme suit :
GET my-index/_search
{
"query": {
"sémantique": {
"field": "description_semantic",
"query": "game about ghosts in medieval times"
}
}
}
Vous venez d'apprendre à synchroniser des données d'une base de données externe vers Elasticsearch et à y ajouter une recherche sémantique !
Étapes suivantes
Merci d'avoir pris le temps d’apprendre à créer votre première requête de recherche avec Python dans Elastic Cloud. Lorsque vous commencerez avec Elastic, vous comprendrez certains éléments opérationnels, de sécurité et de données que vous devrez gérer en tant qu'utilisateur lors du déploiement dans votre environnement.
Prêt à vous lancer ? Profitez d'un essai gratuit de 14 jours sur Elastic Cloud ou essayez ces 15 minutes d'apprentissage pratique sur Search AI 101.