

Elasticsearch : créez votre première requête de recherche avec Python
Aperçu
Présentation du webinar sur Elasticsearch
Elasticsearch met à votre disposition un éventail de techniques de recherche, à commencer par l'algorithme BM25, la norme du secteur pour la recherche textuelle. Il propose également une recherche sémantique alimentée par des modèles d’IA, améliorant les résultats en fonction du contexte et de l’intention.
Elasticsearch fournit des clients officiels pour de nombreux langages de programmation, notamment Python, Rust, Java, JavaScript et d'autres. Ces clients offrent une prise en charge API complète pour l’indexation, la recherche et la gestion des clusters. Ils sont optimisés pour la performance et maintenus à jour avec les versions d'Elasticsearch, ce qui garantit la compatibilité et la sécurité.
Entrons dans le vif du sujet
Dans cet exemple, vous allez indexer quelques documents et les interroger à l'aide de Python. À la fin de ce guide, vous aurez appris à connecter une application back-end à Elasticsearch pour répondre à vos requêtes.
Créer un projet Elastic Cloud
Commencez un essai de 14 jours. Une fois que vous avez créé un compte, suivez les étapes ci-dessous pour apprendre à lancer votre premier projet Elasticsearch Serverless, sélectionnez Elasticsearch.
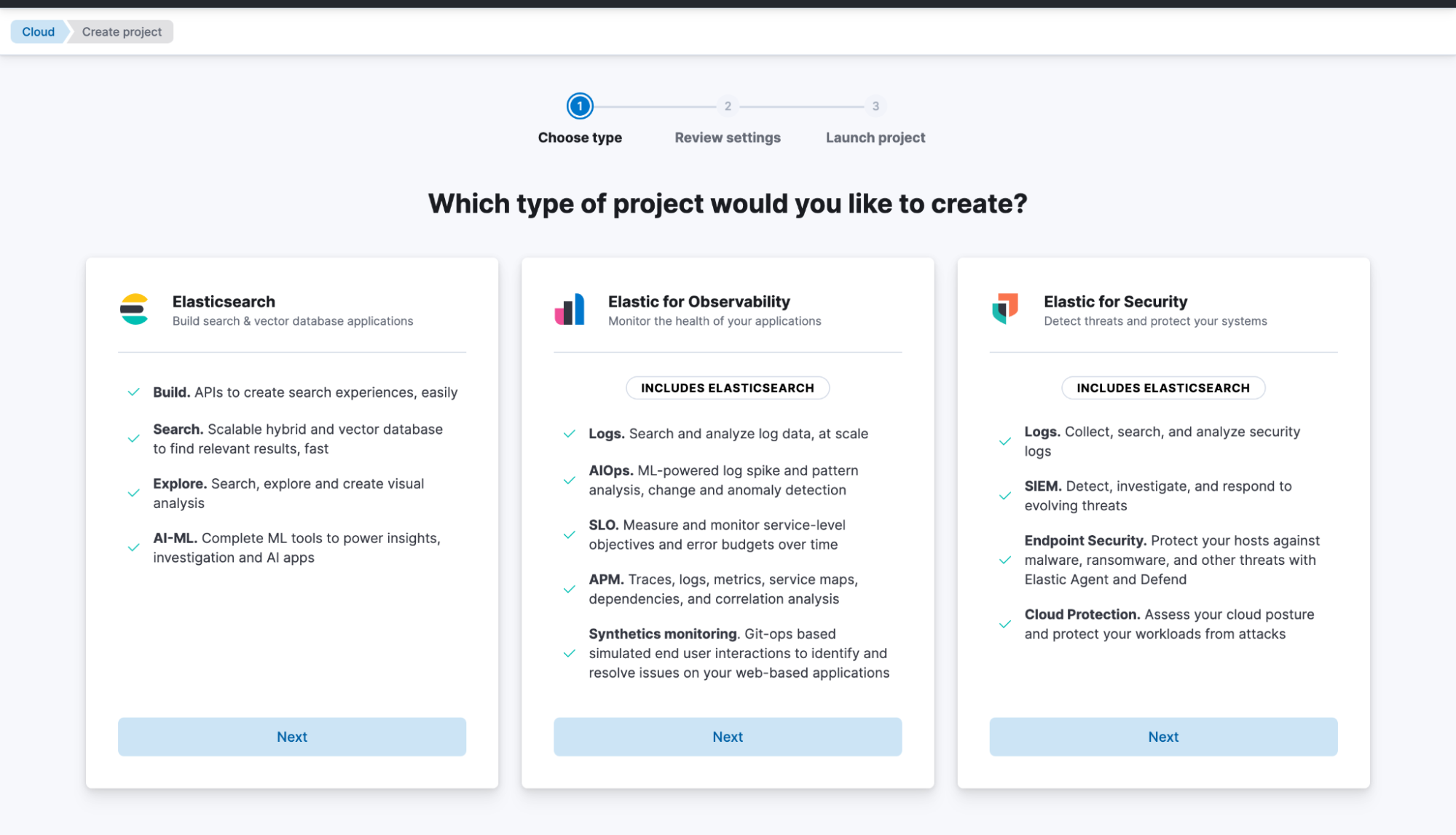
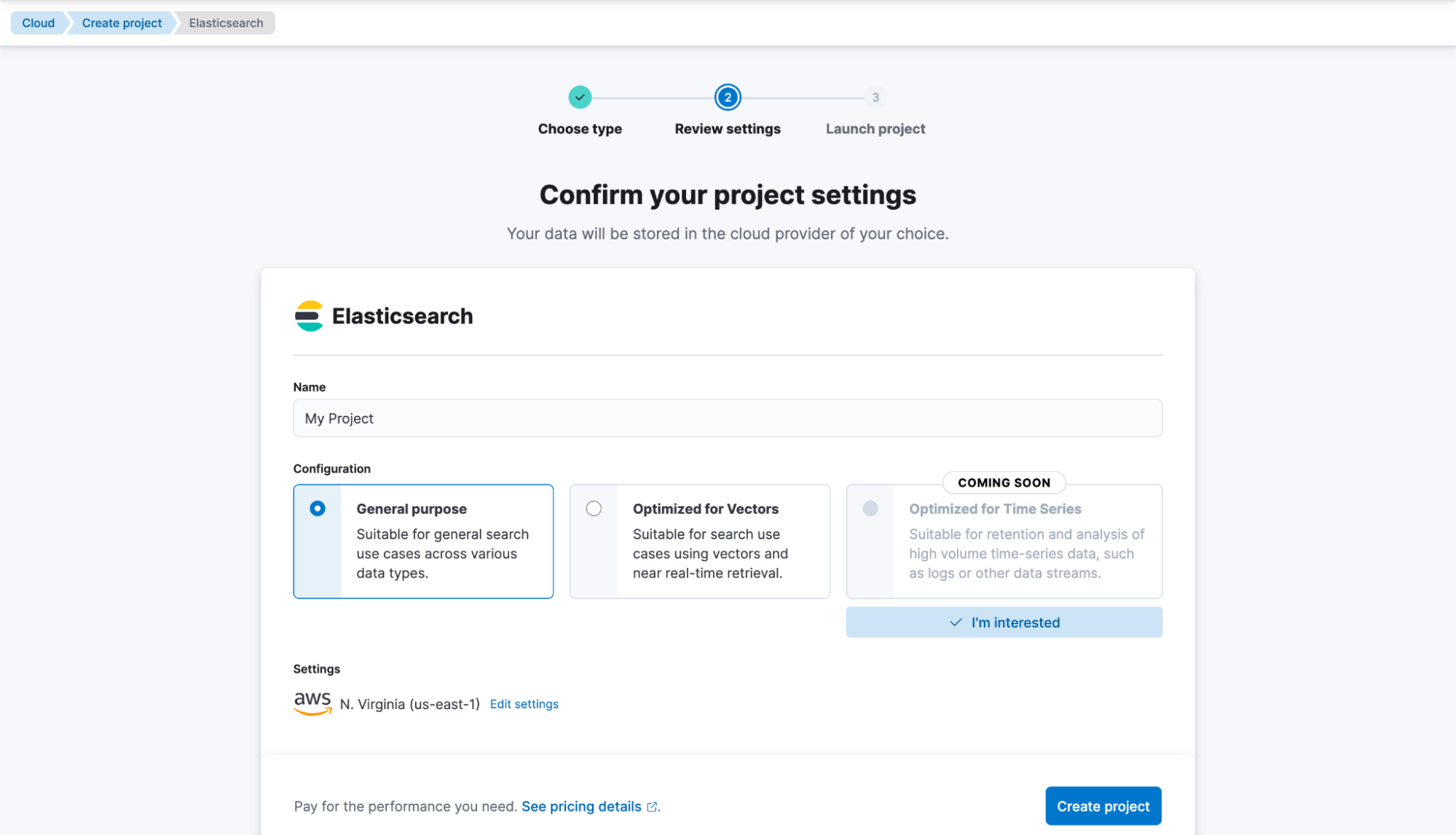
Ensuite, créez General Purpose, donnez-lui un nom, comme My project , et créez-le.
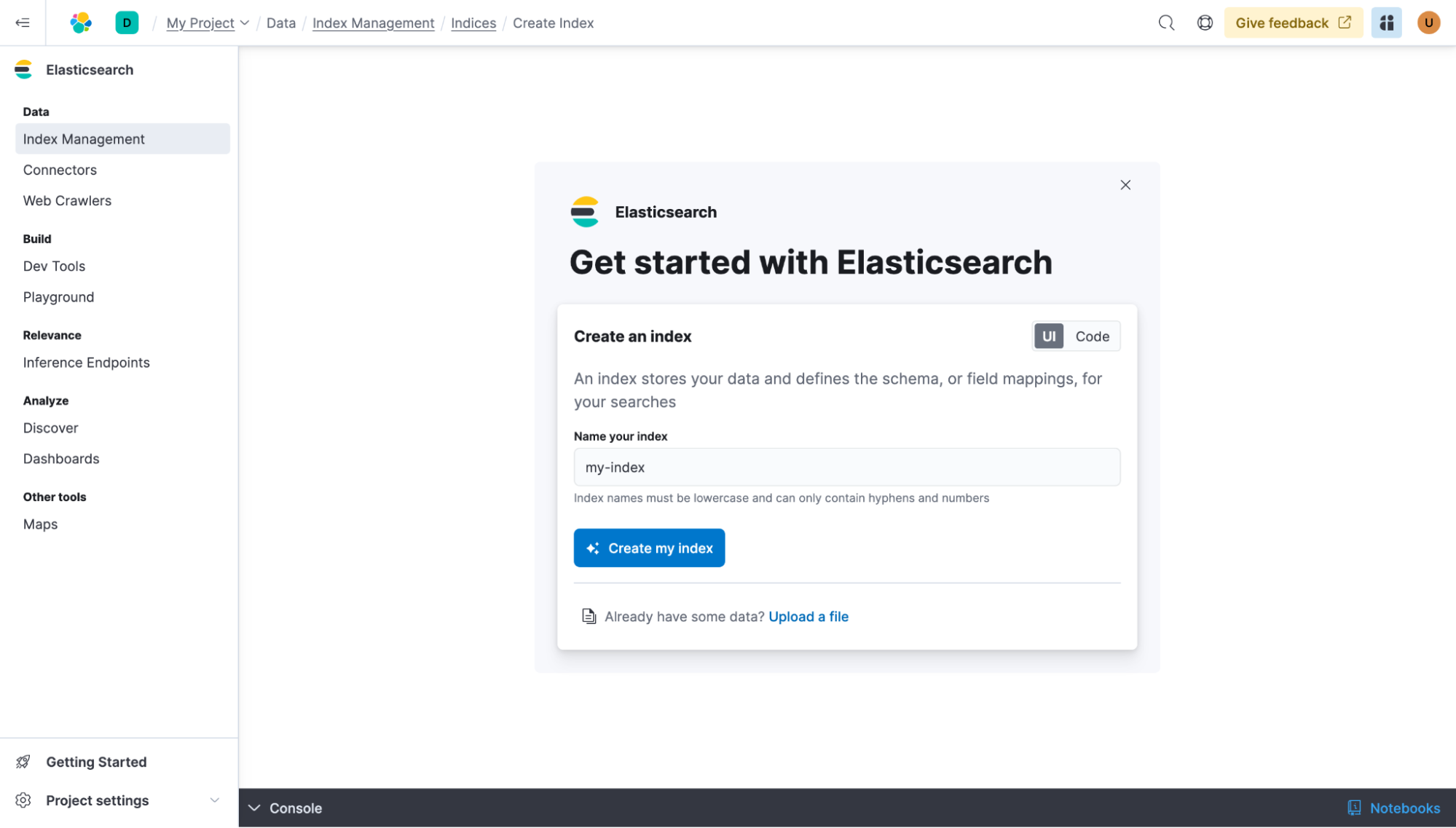
Créons notre premier index Elasticsearch, nous pouvons l'appeler my-index. Sélectionnez Créer mon index.
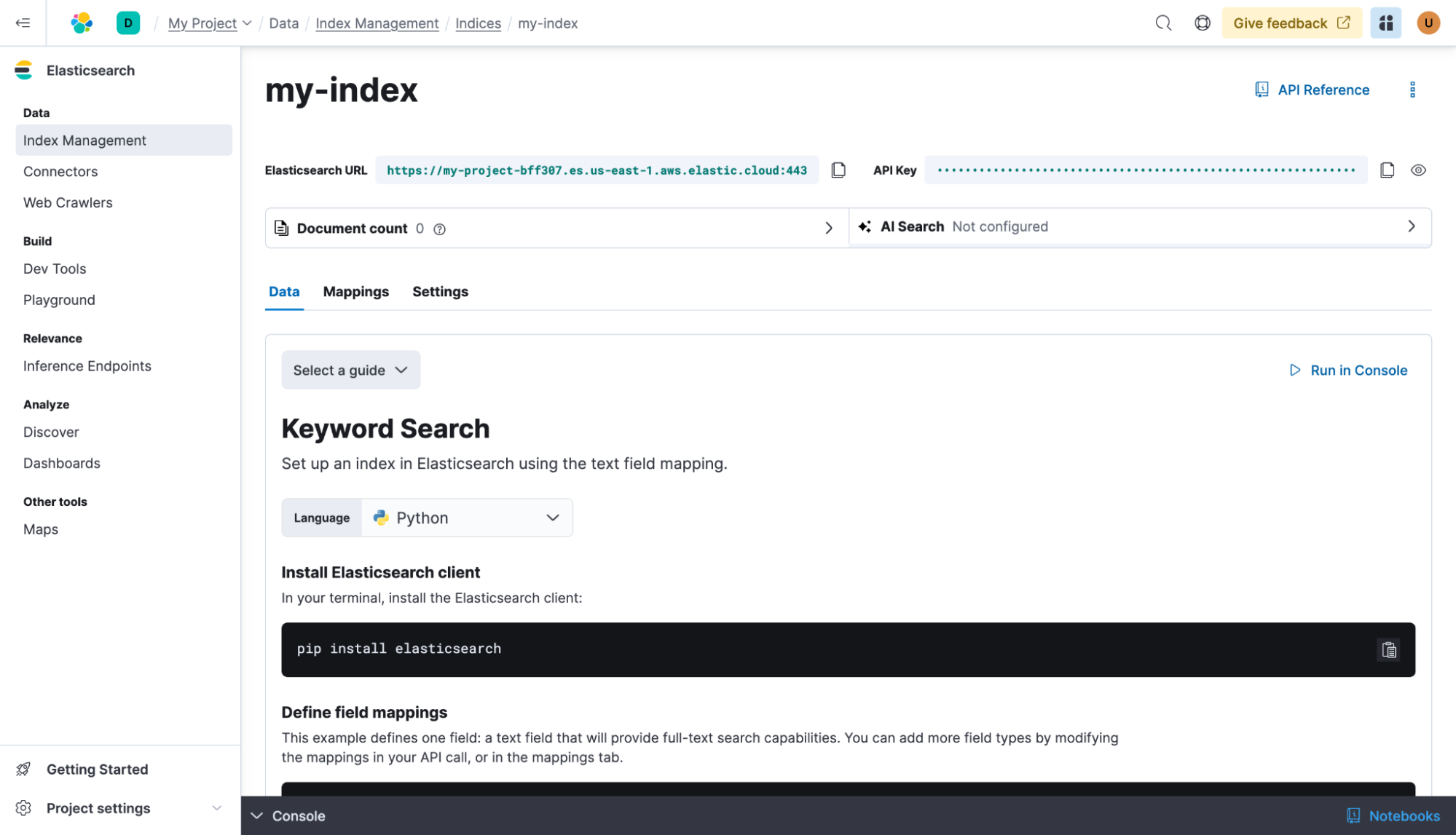
Vous avez créé votre premier index ! Ensuite, créez une clé API pour que votre application puisse communiquer avec Elasticsearch. Sélectionnez votre langue préférée. Pour cet exemple, utilisez Python.
Importez des données dans Elasticsearch
Dans votre terminal, installez le client Elasticsearch à l’aide de pip :
pip install elasticsearch
Copiez votre clé API dans le coin supérieur droit et ajoutez-la à la configuration du client avec l'URL du projet. Nous pouvons déjà créer les mappings pour notre index, qui aura juste un champ de texte nommé de manière créative « texte ».
from elasticsearch import Elasticsearch
client = Elasticsearch(
"https://my-project-bff300.es.us-east-1.aws.elastic.cloud:443",
api_key="YOUR-API-KEY"
)
index_name = "my-index"
mappings = {
"propriétés": {
"text": {
"type": "text"
}
}
}
mapping_response = client.indices.put_mapping(index=index_name, body=mappings)
print(mapping_response)
Ensuite, nous pourrons enfin utiliser les requêtes groupées pour envoyer des données à Elasticsearch. Indexons 3 documents à l'aide d'une requête _bulk. N'oubliez pas d'utiliser les requêtes groupées pour indexer des centaines, voire des milliards de documents, car c'est la solution préférée pour indexer de grandes quantités de documents dans Elasticsearch.
docs = [
{
"text": "Yellowstone National Park is one of the largest national parks in the United States. It ranges from the Wyoming to Montana and Idaho, and contains an area of 2,219,791 acress across three different states. Its most famous for hosting the geyser Old Faithful and is centered on the Yellowstone Caldera, the largest super volcano on the American continent. Yellowstone is host to hundreds of species of animal, many of which are endangered or threatened. Most notably, it contains free-ranging herds of bison and elk, alongside bears, cougars and wolves. The national park receives over 4.5 million visitors annually and is a UNESCO World Heritage Site."
},
{
"text": "Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face."
},
{
"text": "Rocky Mountain National Park is one of the most popular national parks in the United States. It receives over 4.5 million visitors annually, and is known for its mountainous terrain, including Longs Peak, which is the highest peak in the park. The park is home to a variety of wildlife, including elk, mule deer, moose, and bighorn sheep. The park is also home to a variety of ecosystems, including montane, subalpine, and alpine tundra. The park is a popular destination for hiking, camping, and wildlife viewing, and is a UNESCO World Heritage Site."
}
]
bulk_response = helpers.bulk(client, docs, index=index_name)
print(bulk_response)
Vous devriez pouvoir voir les documents dans Elasticsearch.
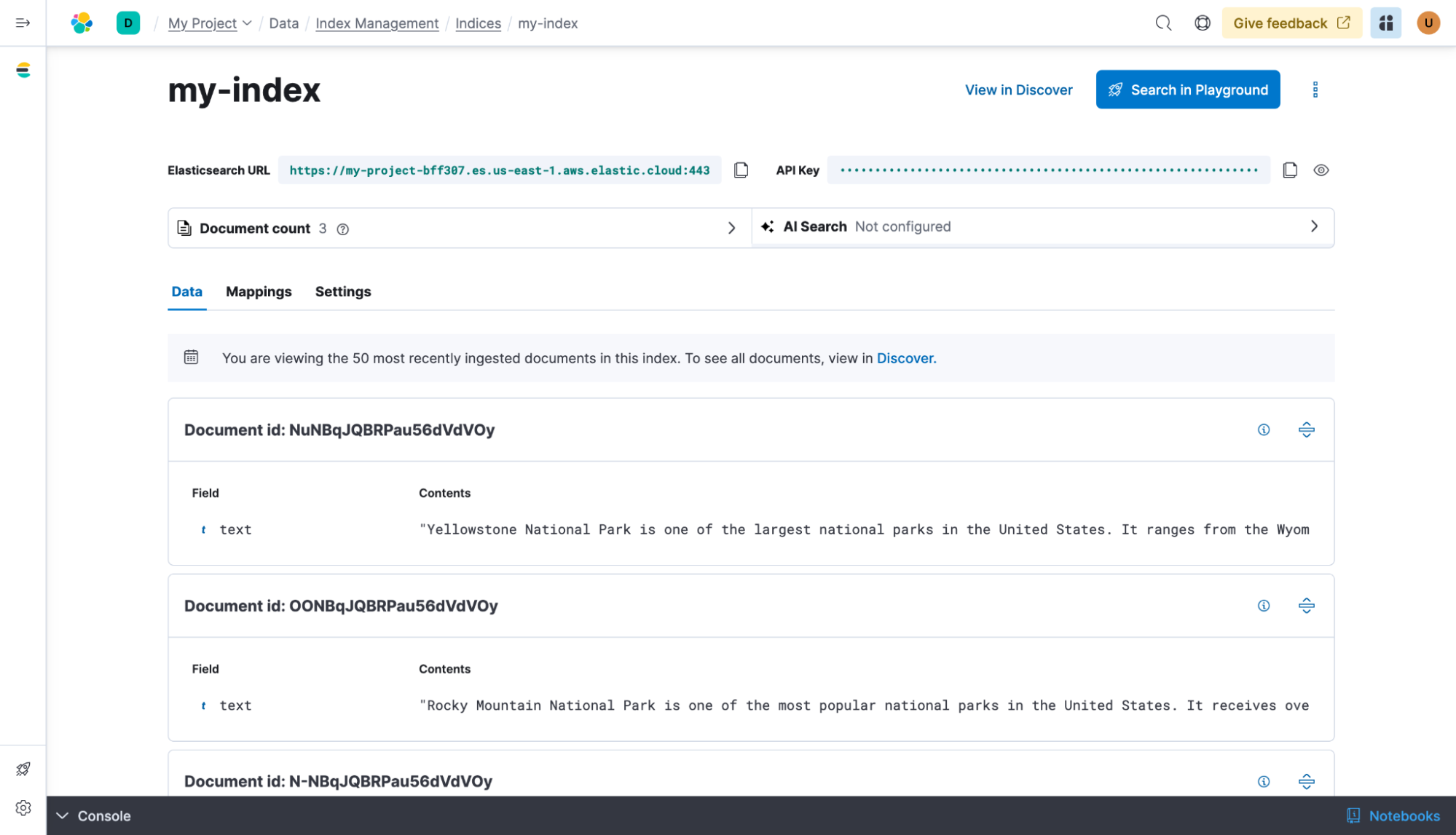
Fonctionnement d'Elasticsearch
Créez votre requête
Créez un nouveau script (par exemple search.py), qui définit une requête et exécute la requête de recherche suivante :
FROM my-index
| WHERE MATCH(text, "yosemite")
| LIMIT 5
Ajoutez cette requête dans client.esql.query :
from elasticsearch import Elasticsearch
client = Elasticsearch(
"https://my-project-bff307.es.us-east-1.aws.elastic.cloud:443",
api_key="YOUR-API-KEY"
)
# Exécutez la requête de recherche
réponse = client.esql.query(
query="""
FROM my-index
| WHERE MATCH(text, "yosemite")
| LIMIT 5
""",
format="csv"
)
print(réponse)
Vérifiez votre résultat :
"Le parc national de Yosemite est un parc national des États-Unis, couvrant plus de 750 000 acres de terres en Californie. Classé au patrimoine mondial de l'UNESCO, le parc est surtout connu pour ses falaises de granit, ses cascades et ses séquoias géants. Yosemite héberge plus de quatre millions de visiteurs la plupart des années, avec un pic de cinq millions de visiteurs en 2016. Le parc abrite une faune variée, notamment des cerfs mulets, des ours noirs et des mouflons de la Sierra Nevada, une espèce en voie de disparition. Le parc s'étend sur 3 108 kilomètres carrés de nature sauvage et constitue une destination prisée des grimpeurs, avec plus de 914 mètres de granit vertical à gravir. Sa falaise la plus célèbre est El Capitan, un monolithe de 914 mètres sur sa face la plus haute."
Vous êtes maintenant prêt à utiliser le client pour interroger Elasticsearch depuis n’importe quel back-end Python, comme Flask, Django, etc. Consultez la documentation du client Elasticsearch Python pour en savoir plus.
Étapes suivantes
Merci d'avoir pris le temps de configurer la recherche sémantique pour vos données à l'aide d'Elastic Cloud. Lorsque vous commencerez avec Elastic, vous comprendrez certains éléments opérationnels, de sécurité et de données que vous devrez gérer en tant qu'utilisateur lors du déploiement dans votre environnement.
Prêt à vous lancer ? Profitez d'un essai gratuit de 14 jours sur Elastic Cloud ou essayez ces 15 minutes d'apprentissage pratique sur Search AI 101.