

Was sind Traces?
Definition von verteiltem Tracing
Verteilte Traces sind eine Art von Telemetriedaten, die eine durchgängige Aufzeichnung auf Codeebene (Transaktion) jeder Nutzeranfrage über den gesamten Pfad einer Anwendung liefern.
Verteiltes Tracing bietet Einblick in den Zustand einer Anwendung, Abhängigkeiten und Interaktionen zwischen Systemkomponenten. Es ist ein wesentlicher Bestandteil der Beobachtbarkeit und des Monitoring der Anwendungsleistung (APM) in cloudnativen Umgebungen.
Traces helfen Site Reliability Engineers (SREs), ITOps- und DevOps-Teams, die durchgängige Bewegung und das Verhalten von Anfragen durch verschiedene Microservices innerhalb eines Systems zu verstehen. Mithilfe von Traces können Informatiker Engpässe und andere Code-Probleme aufspüren, die sich auf die Leistung und das Nutzererlebnis auswirken, und sie für mehr Effizienz optimieren.
Verteiltes Tracing im Vergleich zu traditionellem Tracing
Verteiltes Tracing ist eine Methode zum Beobachten von Anfragen während ihrer Reise durch verteilte Umgebungen.
Eine verteilte Architektur umfasst von vornherein ein komplexes Netz von Diensten. Eine Anfrage durchläuft viele Microservices, die jeweils eine bestimmte Aufgabe erfüllen. Daher ist die Nachverfolgung einer Anfrage in einem verteilten System ein komplexes Unterfangen, das mit dem traditionellen Tracing, das für monolithische Anwendungen verwendet wird, unmöglich wäre.
Herkömmliches Tracing bietet nur begrenzte Einblicke und ist nicht skalierbar. Die herkömmliche Tracing-Methode verwendet Zufallsstichproben von Traces aus jeder Anfrage, was zu unvollständigen Traces führt.
Warum ist Tracing für die Anwendungsentwicklung wichtig?
Tracing ist wichtig für die Anwendungsentwicklung, weil es Informatikern ermöglicht, eine Anfrage durch zahlreiche Microservices zu verfolgen. Die Möglichkeit, jeden Schritt visuell zu verfolgen, macht das Tracing von unschätzbarem Wert. Es hilft bei der Behebung von Fehlern und Leistungsproblemen, indem es Fehler für verschiedene Anwendungen behebt.
Tracing hilft bei Folgendem:
- Identifizieren Sie Probleme schneller: In einem verteilten System ist die Fehlersuche wesentlich schwieriger als in einem monolithischen System. Durch verteiltes Tracing können die Grundursache und der Ort von Anwendungsfehlern schneller ermittelt und Störungen minimiert werden.
- Vereinfachen Sie das Debuggen: Tracing bietet einen umfassenden Überblick darüber, wie Anfragen mit verschiedenen Microservices interagieren, und unterstützt den Debugging-Prozess, selbst in der komplexesten Architektur.
- Verbessern Sie die Zusammenarbeit: In einer verteilten Umgebung arbeiten verschiedene Teams oft an unterschiedlichen Diensten. Eine Ablaufverfolgung identifiziert, wo das Problem aufgetreten ist, und verweist auf das Team, das für die Behebung des Problems verantwortlich ist.
- Beschleunigen Sie die Entwicklung: Mit Tracing können Entwickler wertvolle Einblicke in das Nutzerverhalten gewinnen, die Anwendungsleistung optimieren und die Bemühungen zur Veröffentlichung von Updates und neuen Deployments straffen.
So funktioniert das Tracing
Beim Tracing werden Telemetriedaten einer Anfrage gesammelt, analysiert und visualisiert, während diese über verschiedene Dienste in einer Microservices-Architektur übertragen werden.
Bevor Tracing-Daten (und andere Telemetriedaten) generiert werden, muss eine Anwendung instrumentiert werden. Die Instrumentierung ist ein Prozess, bei dem Code hinzugefügt wird, um Tracing-Daten zu verfolgen. Eine Open-Source-Plattform wie OpenTelemetry (OTel) bietet anbieterneutrale SDKs, APIs und andere Tools zur Instrumentierung der Microservice-Architektur.
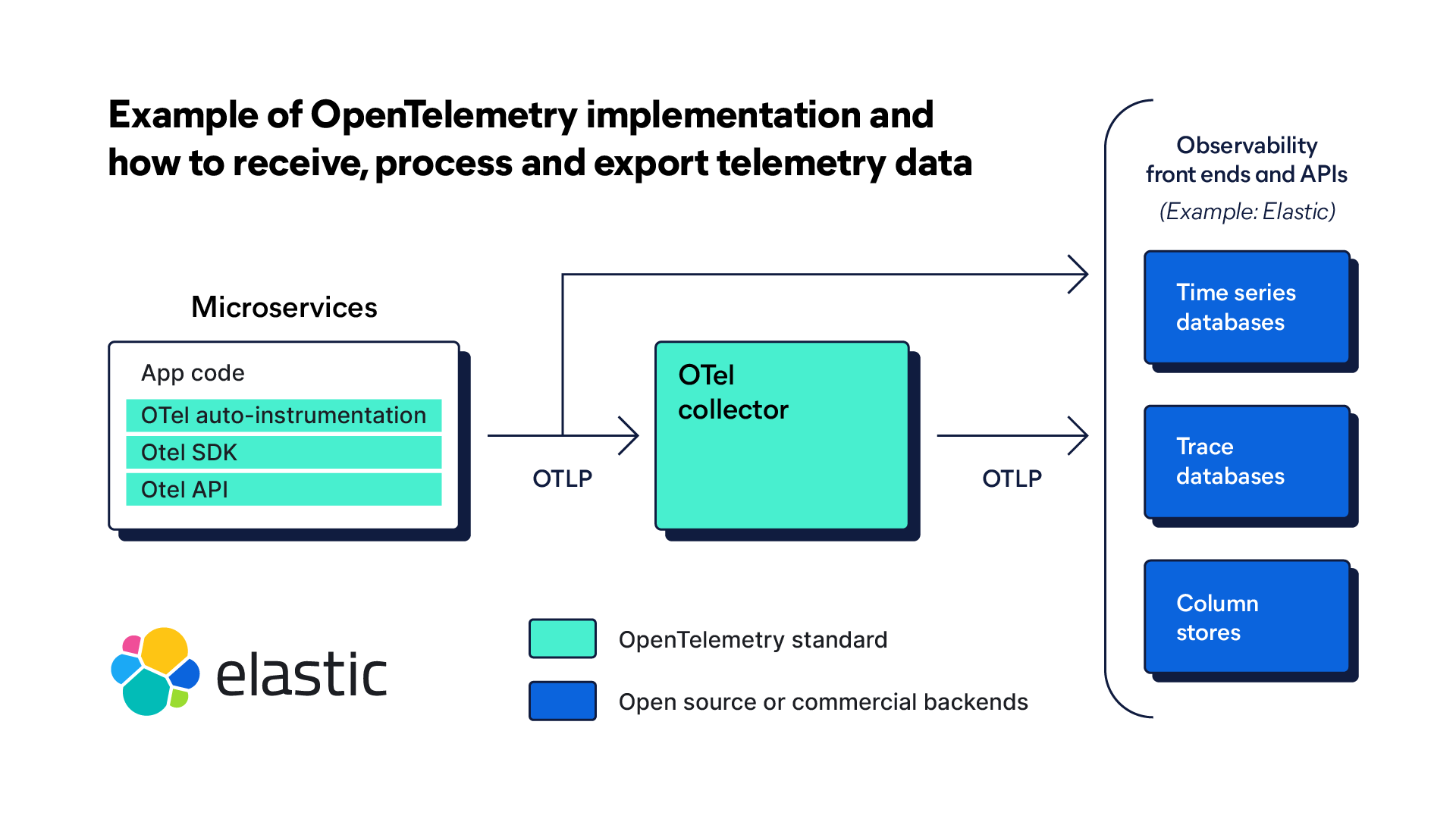
Datenerfassung
Ein ganzheitliches Tool für verteiltes Tracing beginnt mit der Erfassung von Daten, wenn ein Nutzer eine Anfrage initiiert. Jeder Anfrage werden beim Eingang in das System identifizierende Informationen (Trace-ID) hinzugefügt. Diese Identifizierungsinformationen werden auf dem Weg durch die verschiedenen Dienste und Komponenten weitergegeben.
Außerdem wird jeder Schritt während des Anfrageprozesses aufgezeichnet. Der erste wird als übergeordnete Spanne bezeichnet, während jeder nächste als untergeordnete Spanne bezeichnet wird. Jede untergeordnete Spanne wird mit der ursprünglichen Trace-ID, einer eindeutigen Spannen-ID, einem Zeitstempel, Status und anderen relevanten Metadaten codiert. Die Spannen sind hierarchisch organisiert und folgen dem Weg durch die Dienste in der gesamten Umgebung.
Für APM ermöglicht das Instrumentieren einer Anwendung und das Aktivieren der Trace-Erfassung das Sammeln von Tracing-Anwendungskennzahlen oder numerischen Werten, die zur Überwachung der Anwendungsleistung verwendet werden können. Dazu gehören:
- Anforderungsrate – die Anzahl der Anforderungen pro Sekunde
- Fehlerrate – die Anzahl der Anforderungen, die fehlschlagen
- Latenz – die Zeit, die benötigt wird, um auf eine Anfrage zu antworten
- Dauer – die Zeit, die die Anfrage benötigt
- Durchsatz – das Volumen der Anfragen, die eine Anwendung in einem bestimmten Zeitraum verarbeiten kann
Trace-Analyse
Sobald die Anfrage abgeschlossen ist und der Trace alle Daten erfasst, werden die Daten aggregiert. Mithilfe der Daten aus Spannen wie Trace-Identifikatoren, Zeitstempeln und anderen Kontextinformationen können Entwickler Ressourcenengpässe, Latenzprobleme oder Fehler lokalisieren.
Monitoring und Visualisierung
Tracing-Anwendungskennzahlen können bei der Überwachung der Leistung einer Anwendung helfen. Wenn sich etwas ändert, können SREs und DevOps-Teams tätig werden.
Mit künstlicher Intelligenz (KI) oder Machine Learning kann der Monitoring-Prozess teilweise automatisiert werden und Informatiker werden auf potenzielle Probleme aufmerksam gemacht, bevor sie auftreten. Ein KI-Assistent kann außerdem dabei helfen, tiefer in die Trace-Analyse einzudringen und durch die Korrelation von Beobachtungsdaten aus anderen Quellen schnell zugrunde liegende Probleme zu untersuchen.
Schließlich werden alle Spannen in einem Wasserfalldiagramm visualisiert: eine übergeordnete Spanne an der Spitze und darunter verschachtelte untergeordnete Spannen. Dieses Diagramm zeigt aus der Vogelperspektive, was eine Anwendung tat, während sie versuchte, auf eine Anfrage zu antworten. Dann können Informatiker verstehen, in welchen Teilen eines verteilten Systems Leistungsprobleme, Fehler oder Engpässe auftreten.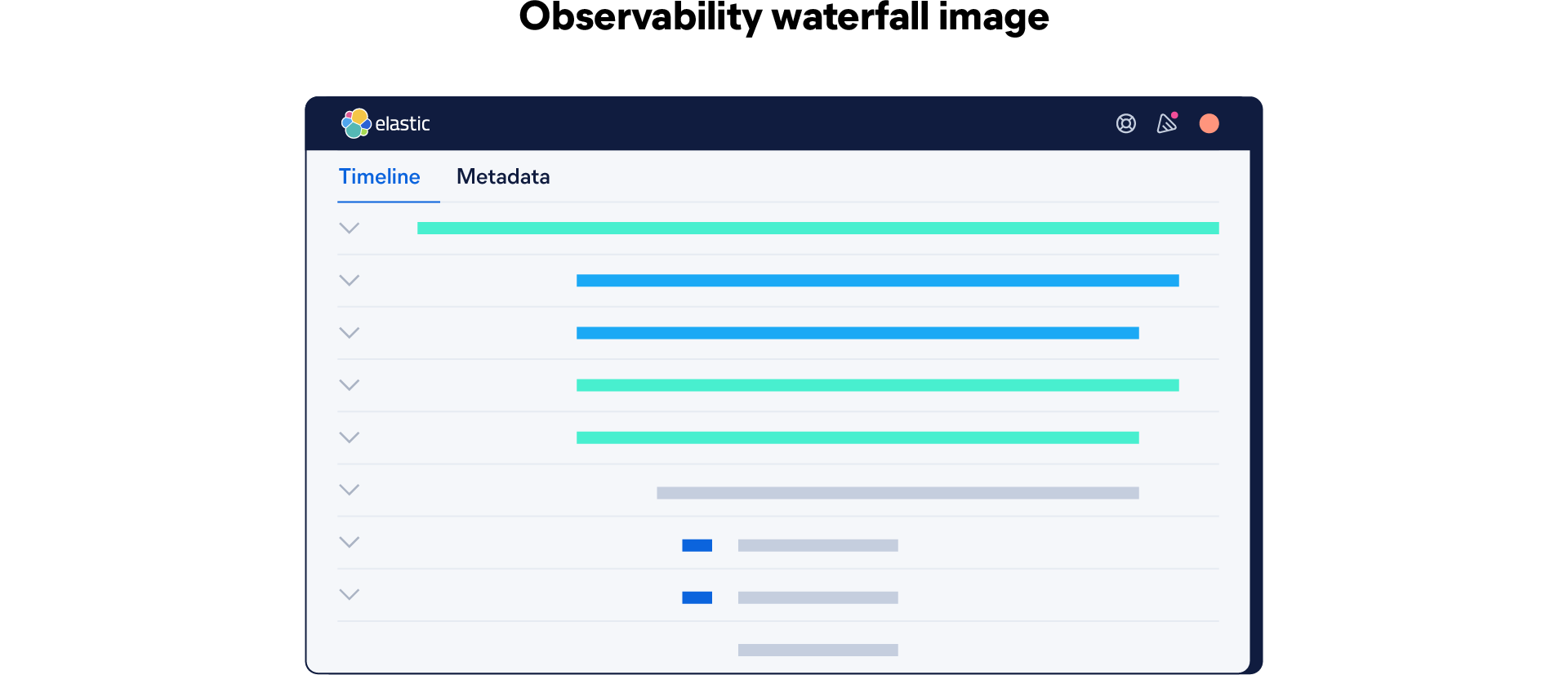
Offene Standards für Tracing in OpenTelemetry
OpenTelemetry ist ein Open-Source-Beobachtungsframework, das aus Tools, APIs und SDKs besteht. OTel ermöglicht SREs, DevOps und IT-Teams, Telemetriedaten einschließlich Traces in einem einzigen, einheitlichen Format zur Analyse zu instrumentieren, zu sammeln und zu exportieren.
Die Cloud Native Computing Foundation (CNCF) hat OTel entwickelt, um standardisierte Protokolle, Schemata und Tools zum Sammeln und Weiterleiten von Telemetriedaten an Beobachtbarkeitsplattformen bereitzustellen. Mit einem starken Fokus auf Traces ist OTel das Ergebnis einer Fusion zweier früherer CNCF-Projekte, OpenTracing und OpenCensus. Sie wurden entwickelt, um einen einheitlichen Standard für die Code-Instrumentierung und das Routing von Telemetriedaten an ein Backend für Beobachtbarkeit festzulegen.
Seit 2019, als die beiden Projekte zusammengelegt wurden, haben sowohl die Open-Source-Communities als auch Unternehmen OTel übernommen, weil es ein einheitliches Format für die Instrumentierung bietet und zukunftssicher ist.
Vor OpenTelemetry und seinen offenen Standards waren Beobachtbarkeitsdaten oft uneinheitlich und schwer zu korrelieren. In einer verteilten Umgebung mussten DevOps und IT verschiedene Bibliotheken instrumentieren, die die verschiedenen Anwendungen und Dienste ihres Unternehmens in mehreren Programmiersprachen unterstützten. Häufig war jede Codeinstrumentierung, jedes APM oder jedes Ablaufverfolgungstool proprietär, was zu einer Vielzahl von Problemen für das verteilte Tracing führte. Wenn es keinen Standard und kein einzelnes Tool zum Sammeln (und Exportieren) von Traces aus allen Anwendungen gibt, wird die Aufgabe der Informatiker, Leistungsprobleme oder Fehler zu finden, zu einer Herausforderung.
Bei OTel hingegen müssen Informatiker den Code nicht neu instrumentieren, um Trace-Daten von verschiedenen Diensten zu verfolgen, noch müssen sie Telemetriedaten bei jeder Änderung manuell umleiten. Es gibt nur ein Open-Source-Framework für Beobachtbarkeit und Monitoring-Tools, das OpenTelemetry-kompatibel ist.
Mit dem Aufkommen neuer Technologien wie z. B. tiefere Integrationen mit KI zur Anomalieerkennung und generativer KI wird OpenTelemetry weiterhin ein einziges, unterstütztes Framework für das verteiltes Tracing bieten.
Zu den OTel-Standards für das Tracing gehören:
- Ein einheitlicher Satz von APIs und Konventionen zum Sammeln von Tracing-Daten
- Spanne wird als eine Kerneinheit der Ablaufverfolgung definiert
- Semantische Konventionen für die Benennung von Spannen und das Hinzufügen von Attributen
- Ein Kontextmechanismus zum Verknüpfen von Spannen über verschiedene Dienste hinweg
- Unterstützung für verschiedene Programmiersprachen
Weitere Informationen zu OpenTelemetry mit Elastic
Traces, Kennzahlen, Logs und Profile
Telemetriedaten – Logs, Metriken und Traces – bieten vollständige Beobachtbarkeit des Verhaltens von Anwendungen, Servern, Diensten oder Datenbanken in einer verteilten Umgebung. Logs, Metriken und Traces – auch bekannt als die drei Säulen der Beobachtbarkeit – erstellen eine vollständige, korrelierte Aufzeichnung jeder Nutzeranfrage und Transaktion.
Jeder der drei Datentypen liefert wesentliche Informationen über die Umgebung. Gemeinsam helfen sie DevOps, IT- und SRE-Teams dabei, die Leistung des gesamten Systems in Echtzeit und in der Vergangenheit zu verfolgen.
Traces
Traces sind detaillierte Aufzeichnungen des Pfads einer Anfrage durch das gesamte verteilte System, um Kontext bereitzustellen. Durch das Zusammenführen isolierter Daten und die Aufzeichnung sämtlicher Aktionen eines Nutzers helfen Traces den Informatikern dabei, Engpässe zu entdecken, Anwendungen zu debuggen und zu überwachen, sowie Abhängigkeiten und Interaktionen zwischen Systemkomponenten zu verstehen.
Logs
Logdateien sind die mit Zeitstempeln versehenen Aufzeichnungen von Ereignissen und Systemnachrichten. In der Regel werden Logs zur Problembehandlung und zum Debuggen verwendet. Sie bieten Einblicke in das Systemverhalten und helfen bei der Identifizierung von Problemen.
Darüber hinaus verfügen die meisten Programmiersprachen über integrierte Logging-Funktionen. Daher neigen Informatiker dazu, weiterhin ihre vorhandenen Logging-Frameworks zu verwenden.
Weitere Informationen zu Logging und OpenTelemetry
Metriken
Kennzahlen sind numerische Werte, die den Zustand oder die Leistung eines Systems über einen bestimmten Zeitraum darstellen. Kennzahlen sind die wichtigsten Leistungsindikatoren. DevOps und andere Teams verwenden sie, um die Systemintegrität zu überwachen, Trends zu erkennen und Warnungen auszulösen.
Profile: die zukünftige vierte Säule moderner Beobachtbarkeit
Kennzahlen, Logs und Traces bieten wertvolle Einblicke darin, was wo passiert. Es ist auch wichtig zu verstehen, warum sich das System so verhält: Warum gibt es einen Leistungsengpass oder eine verschwenderische Berechnung? Hier kommt die kontinuierliche Profilerstellung ins Spiel. Sie hilft dabei, einen umfassenden Überblick über das System zu erhalten, und bietet ein tieferes Maß an Transparenz bis auf die Codeebene.
Mehr über die Säulen der Beobachtbarkeit erfahren
So implementieren Sie verteiltes Tracing
Verteilte Traces sind für das Monitoring und die Fehlerbehebung komplexer Systeme und verteilter Anwendungen unerlässlich. Vor der Implementierung von verteiltem Tracing ist es wichtig, die Ziele und Anforderungen des Tracings zu definieren und kritische Dienste und Anforderungspfade zu identifizieren. Hier sind fünf Schritte für eine erfolgreiche Implementierung von verteiltem Tracing:
- Wählen Sie ein Tracing-Tool, wie z.B. OpenTelemetry (das mittlerweile standardisierte Framework zur Erfassung von Traces, Kennzahlen und Logs). Es sollte mit Ihrem bestehenden Technologie-Stack kompatibel und zukunftssicher sein.
- Instrumentieren Sie Services und Anwendungen. Dazu müssen Sie Tracing-Code zu Ihrer Codebasis hinzufügen und Traces (Spannen) in Ihrer Anwendung definieren.
- Sammeln Sie Traces, indem Sie eine Anfrage zum Sammeln von Daten initiieren. Stellen Sie durch Kontext-Propagierung sicher, dass Traces korrekt und vollständig sind, ein wesentlicher Bestandteil des verteilten Tracings.
- Exportieren Sie Traces für Monitoring, Analyse und Visualisierung an Ihren gewählten Backend- oder Cloud-Tracing-Dienstleister.
- Identifizieren Sie Leistungsengpässe, Ineffizienzen und Fehler. Trace-Daten können dabei helfen, Fehler zu erkennen, langsam arbeitende Dienste zu finden und den Datenfluss zwischen den Diensten zu visualisieren.
APM und verteiltes Tracing mit Elastic
Monitoring der Anwendungsleistung (APM) spielt eine wichtige Rolle in der modernen Beobachtbarkeit. Es führt Sie durch all Ihre Telemetriedaten, indem es Kontext bereitstellt und die Ursachenanalyse mit Machine Learning verbessert.
Nutzen Sie Elastic Observability und die Leistungsfähigkeit der Suche, um die Codequalität mit durchgängigem verteilten Tracing zu verbessern. Erfassen und analysieren Sie verteilte Transaktionen, die sich über Microservices, serverlose und monolithische Architekturen erstrecken, einschließlich Unterstützung für AWS Lambda, automatische Instrumentierung und gängige Sprachen wie Java, .NET, PHP, Python, Go und viele mehr. Minimieren Sie Betriebsausfallzeiten und optimieren Sie die Customer Experience durch Kommentierung von Transaktionen mit Kundendaten und Deployment-Markierungen.
Traces-Ressourcen
- [Blog] Beobachtbarkeitsmetriken verstehen: Arten, goldene Signale und Best Practices
- [Blog] Die drei Säulen der Beobachtbarkeit: einheitliche Logs, Kennzahlen und Traces
- [Technischer Leitfaden] Beispiel-Trace-Zeitleiste
- [Technischer Leitfaden] Traces