

监测和优化 AI 性能、成本、安全性和可靠性
通过一目了然的仪表板了解全貌
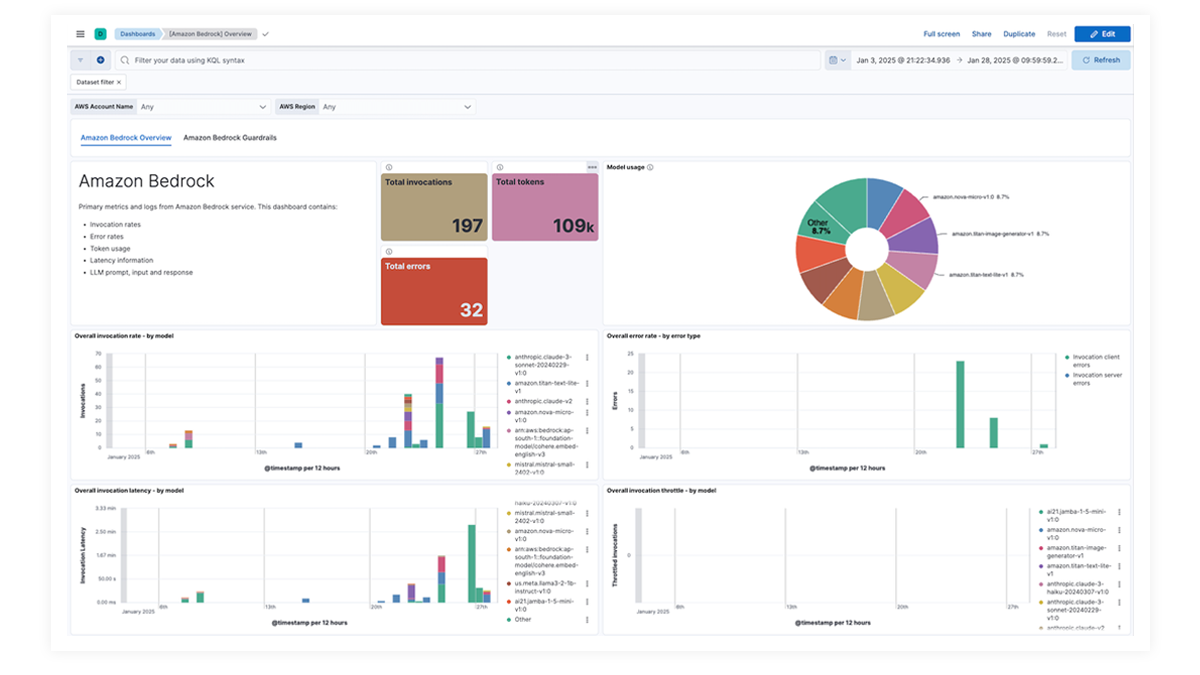
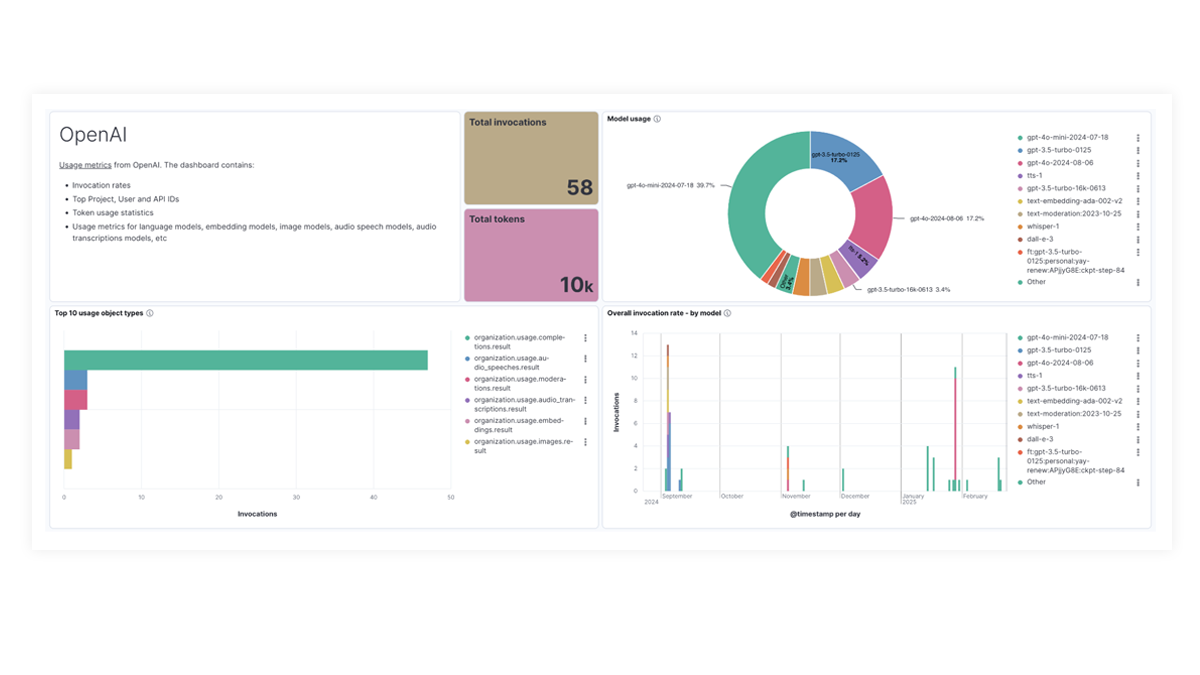
OpenAI、AWS Bedrock、Azure OpenAI 和 Google Vertex AI 的预建仪表板提供有关调用次数、错误率、延迟、利用率指标和令牌使用情况的全面见解,使 SRE 能够识别和解决性能瓶颈、优化资源利用率并维护系统可靠性。
性能缓慢?查明根本原因
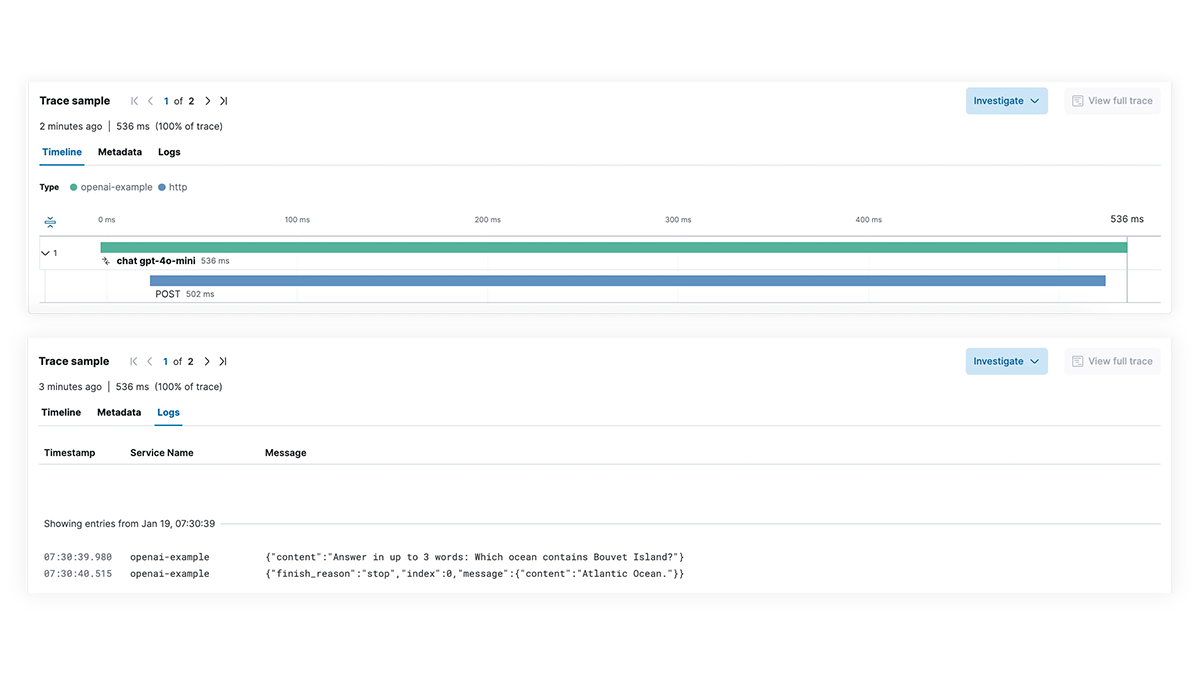
全面了解集成生成式 AI 功能的应用程序的 LLM 执行路径的每个步骤。通过端到端跟踪、服务依赖关系映射以及对 LangChain 请求、失败的 LLM 调用和外部服务交互的可见性,实现更深入的调试。快速排除故障和延迟峰值,确保最佳性能。
AI 安全问题?获取对提示和响应的可见性
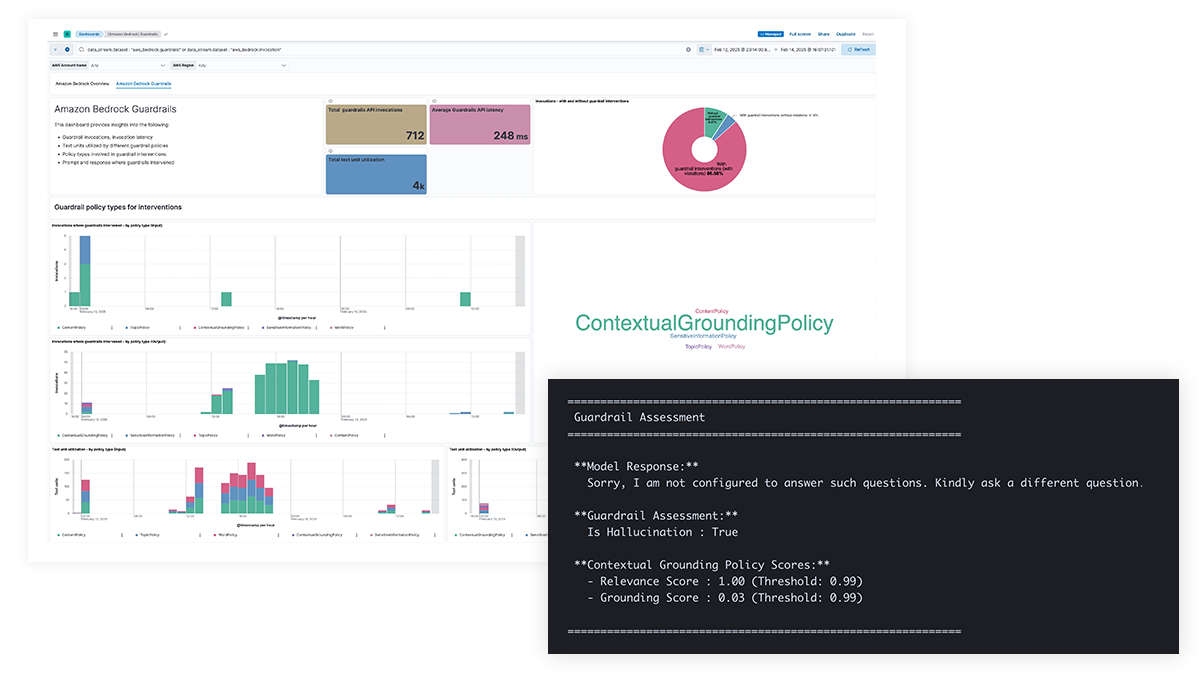
我们可以提高 LLM 提示和响应的透明度,以防止敏感信息泄露,避免有害或不良内容及道德问题,并解决事实错误、偏见和幻觉问题。对 Amazon Bedrock Guardrails 和 Azure OpenAI 内容过滤的支持可实现基于策略的干预并提供上下文基础以提高模型的准确性。
难以跟踪成本?查看每个模态的使用详情
企业需要了解令牌使用情况、高成本查询和 API 调用、低效提示结构以及其他成本异常情况,以优化 LLM 支出。Elastic 可为多模态模型(包括文本、视频和图像)提供分析见解,让团队能够有效地跟踪和管理 LLM 成本。

开始使用 LLM 可观测性
第 2 步:即时仪表板——只需几秒,即时可用
第 3 步:创建警报——将数据转化为行动
生成式 AI 应用可见性
通过第三方跟踪库以及所有主要 LLM 服务托管模型的即时可见性,使用 Elastic 对 AI 应用进行端到端深入了解。












LLM observability dashboard gallery
The OpenAI integration for Elastic Observability includes prebuilt dashboards and metrics so you can effectively track and monitor OpenAI model usage, including GPT-4o and DALL·E.
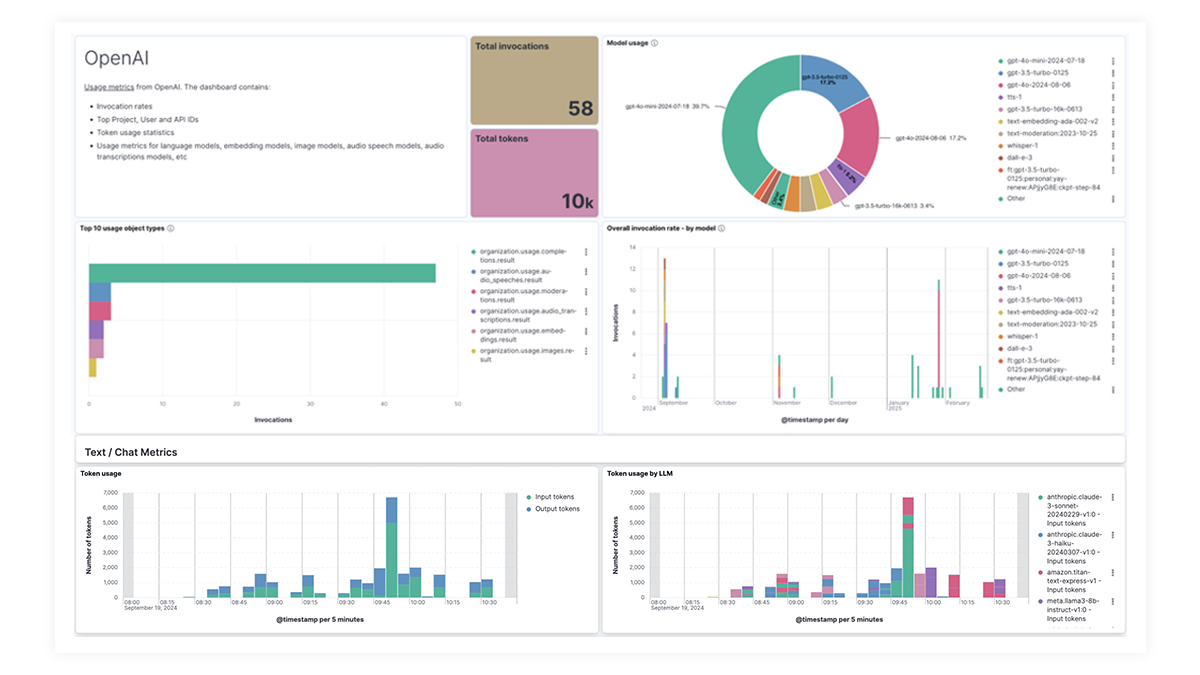
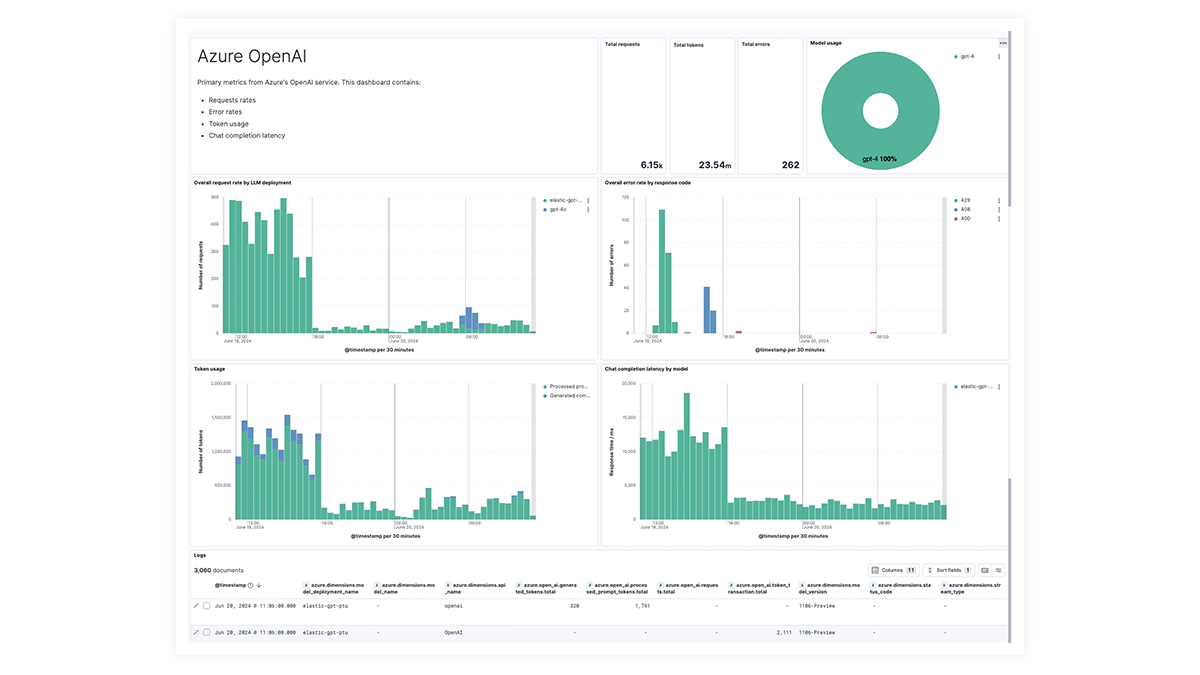
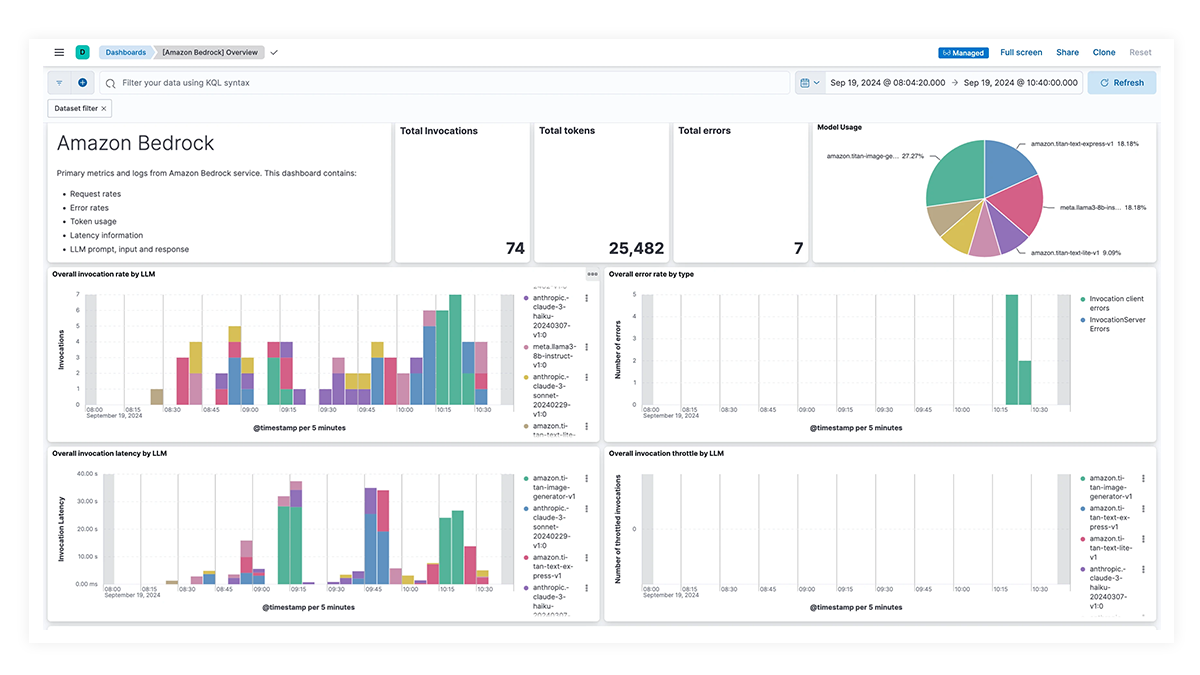
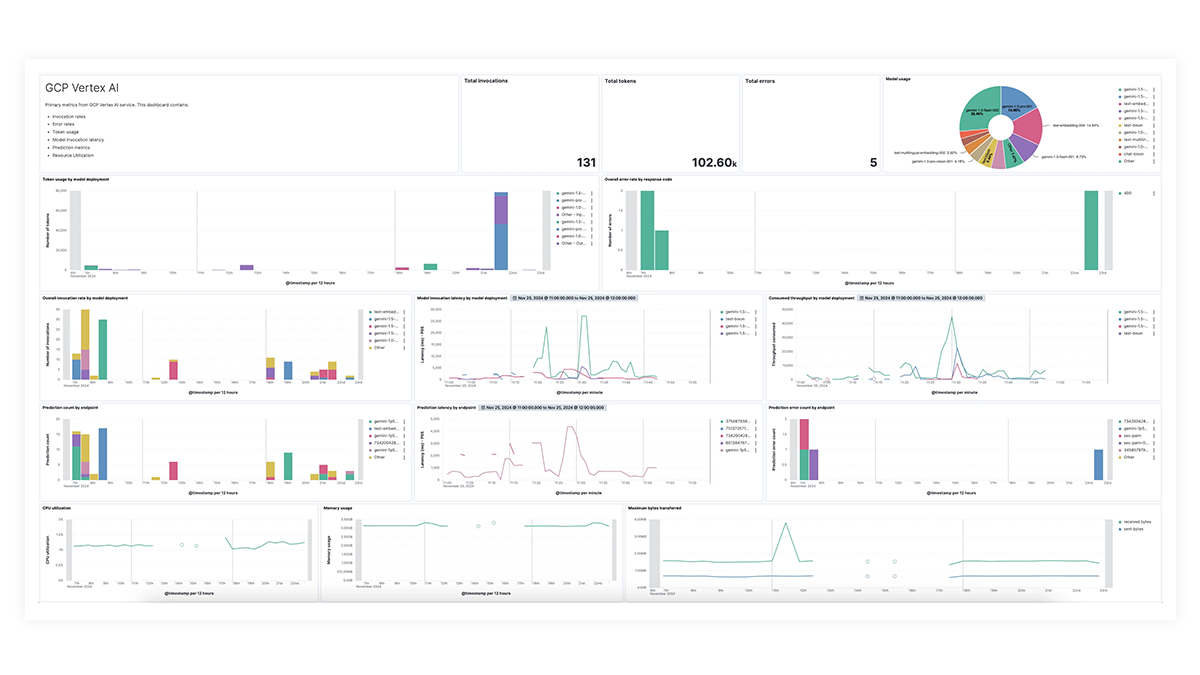
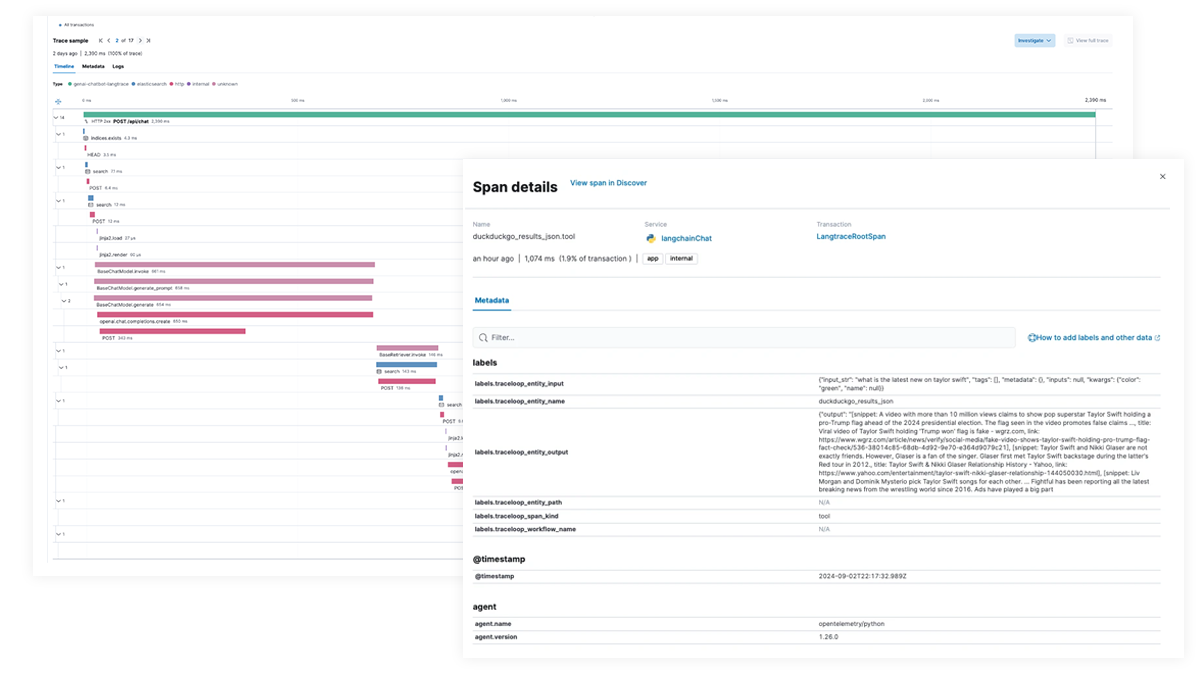
利用 EDOT 和第三方库进行端到端跟踪
使用 Elastic APM 通过 OpenTelemetry 分析和故障排查 LangChain 应用。EDOT(Java、Python、Node.js)或第三方跟踪库(如 LangTrace、OpenLIT 或 OpenLLMetry)可以支持此功能。
欢迎亲自试用 Elastic 聊天机器人 RAG 应用!这个示例应用结合了 Elasticsearch、LangChain 和各种 LLM,通过 ELSER 和您的私有数据为聊天机器人提供支持。
不局限于 LLM 可观测性

APM

数字体验监测

日志分析

基础架构监测

AI Assistant

工具整合

