

Observabilité des LLM
Monitorer et optimiser les performances, les coûts, la sécurité et la fiabilité de l’IA
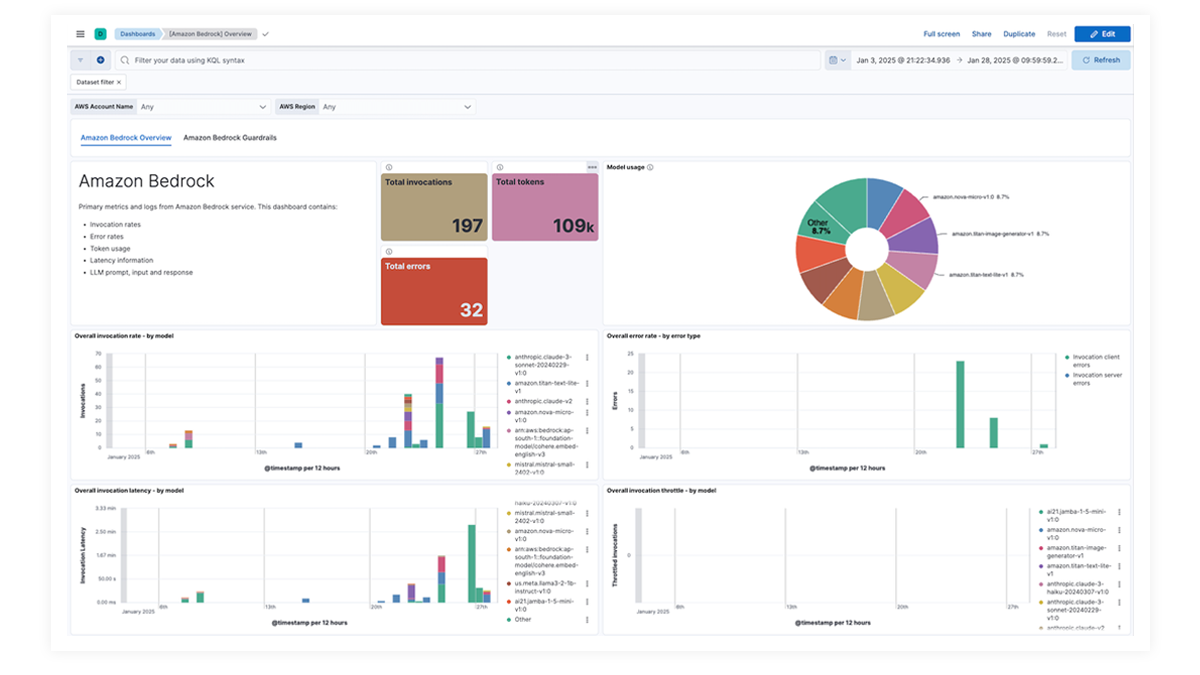
Obtenez une vue d’ensemble avec des tableaux de bord en un coup d’œil
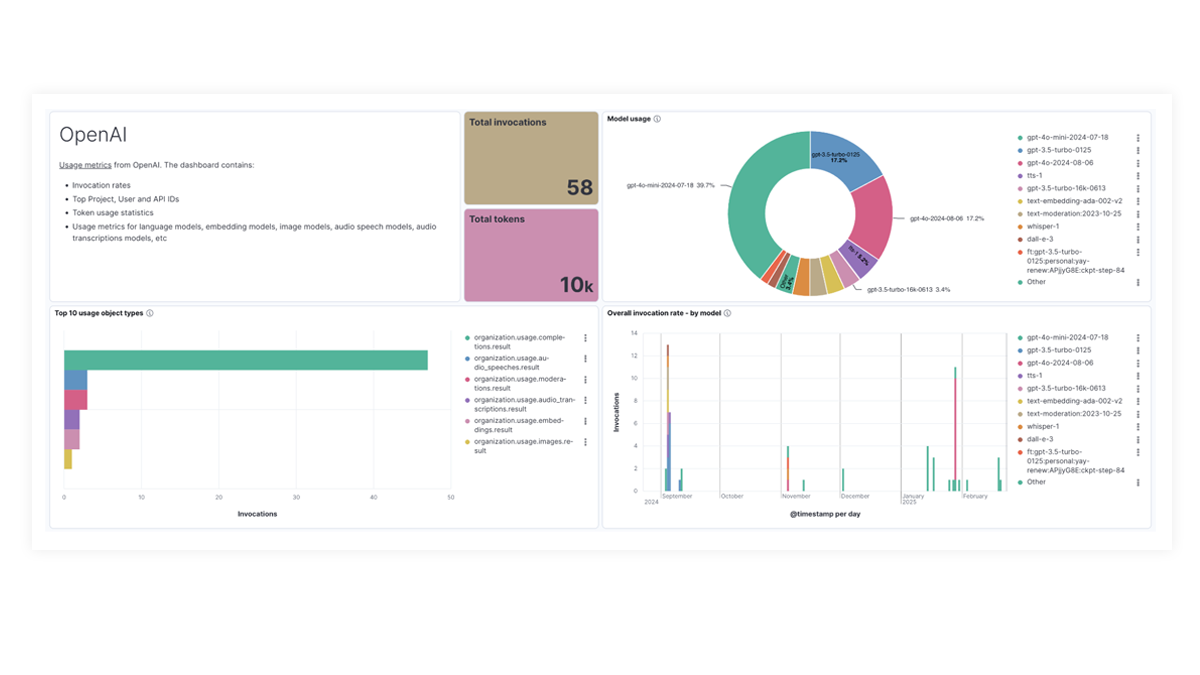
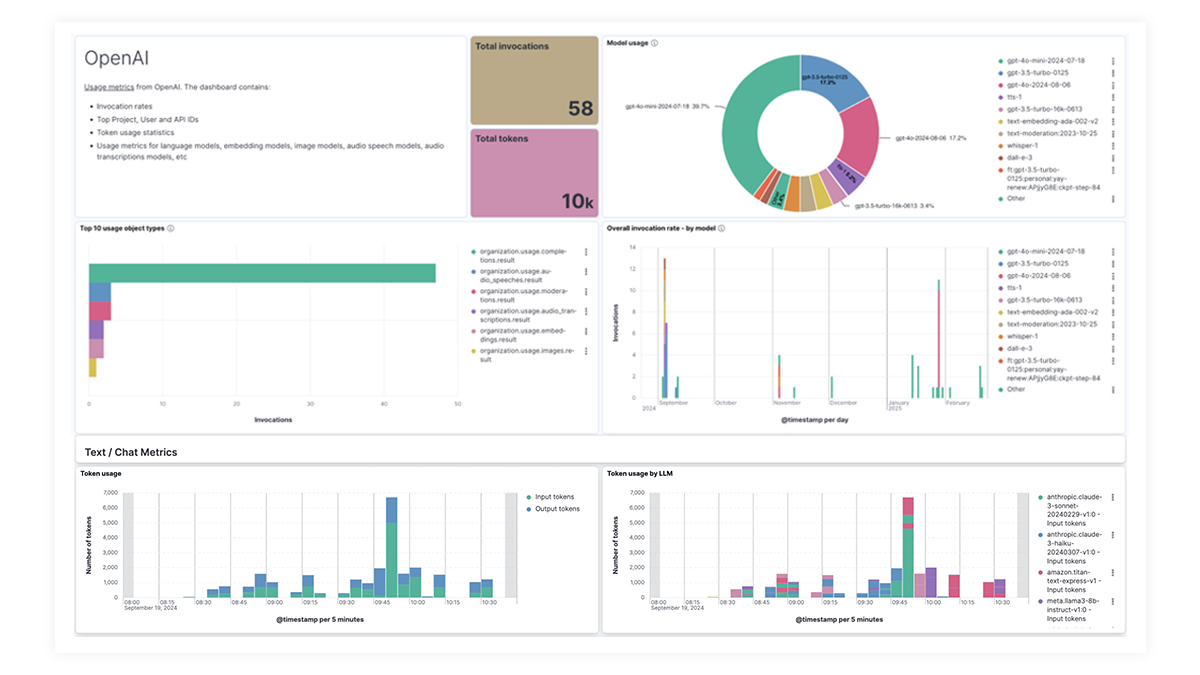
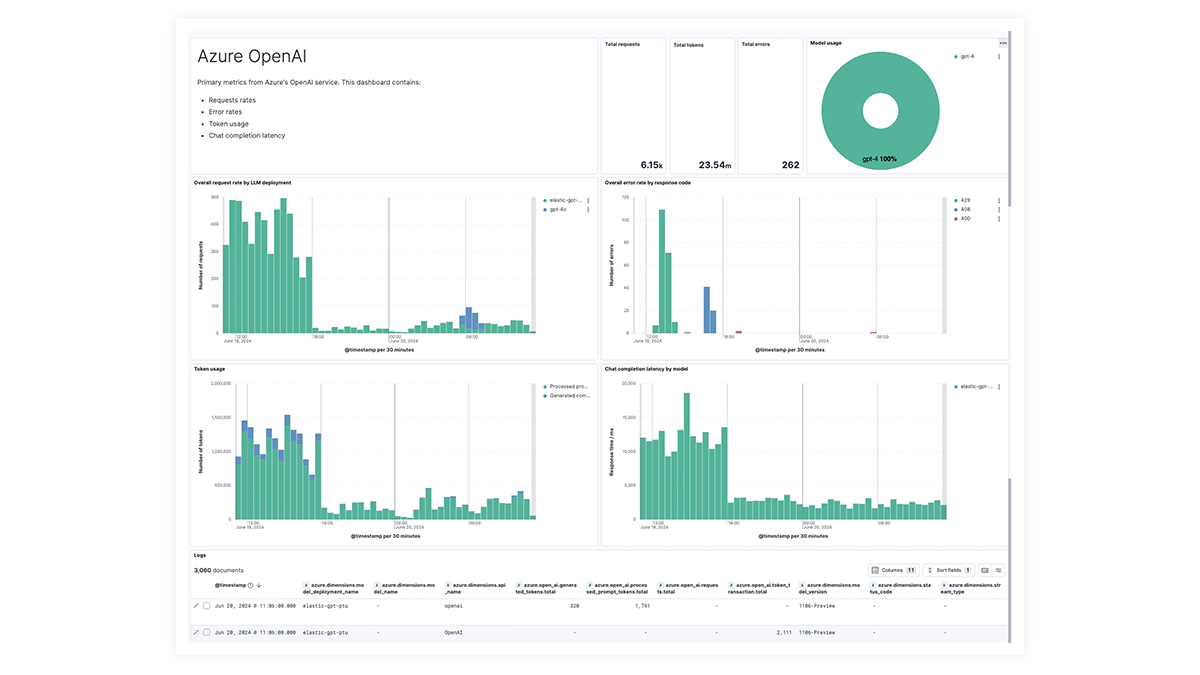
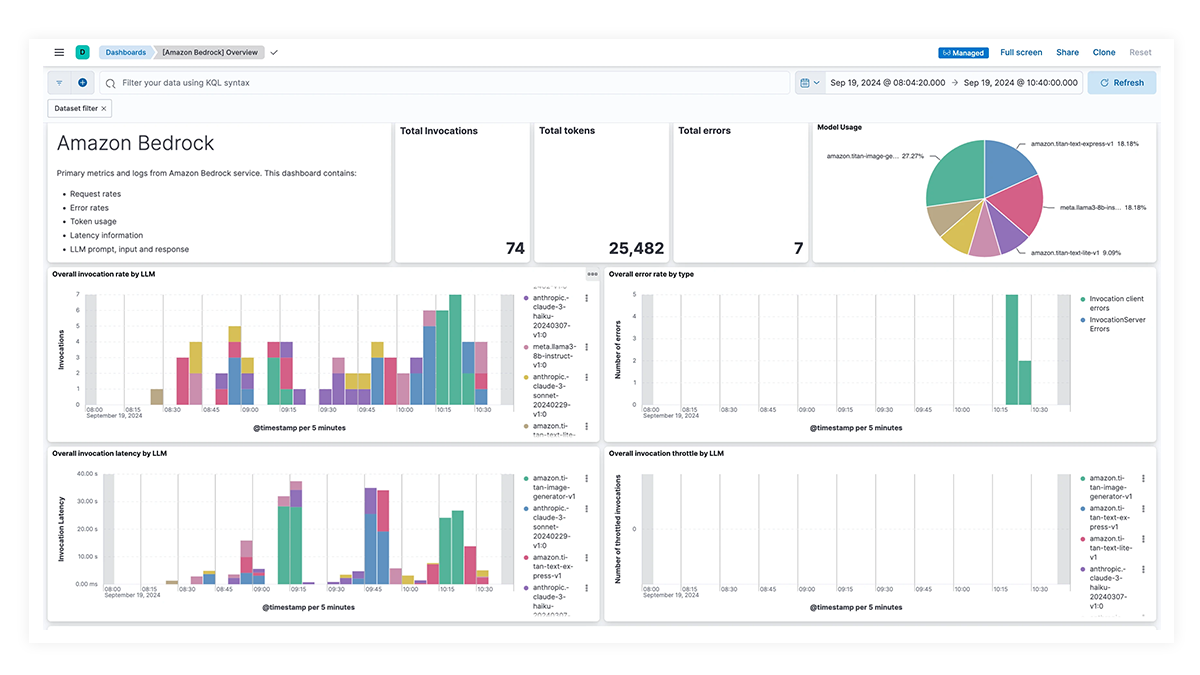
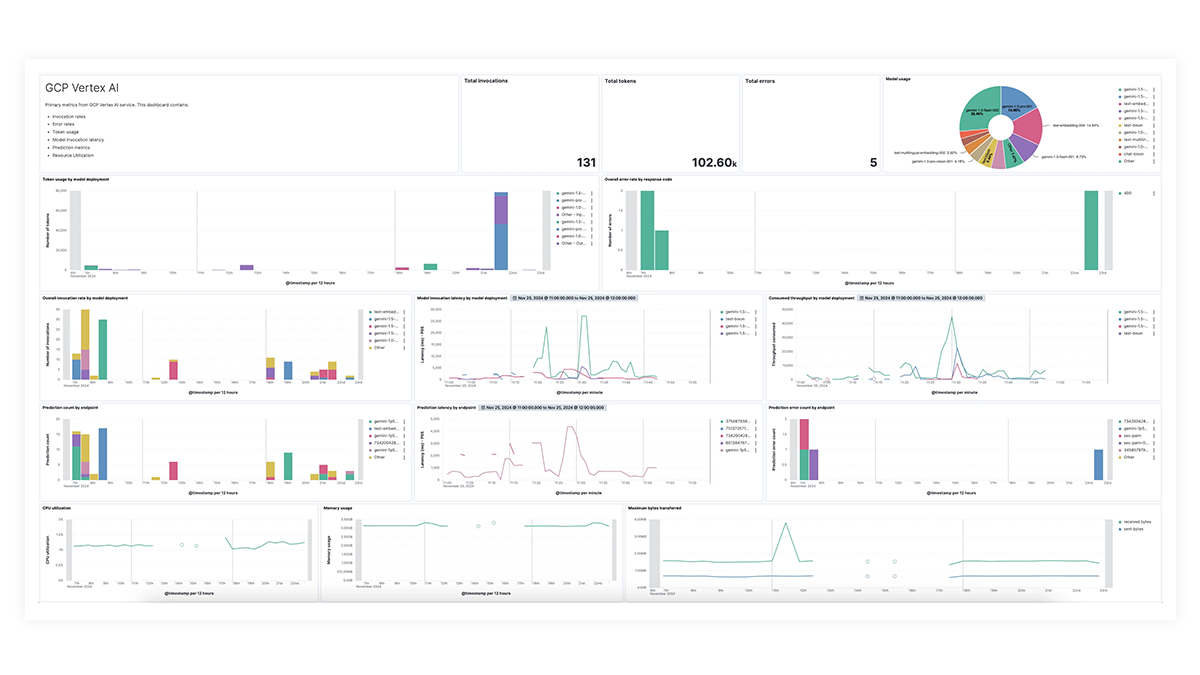
Les tableaux de bord prédéfinis pour OpenAI, AWS Bedrock, Azure OpenAI et Google Vertex AI offrent des informations complètes sur le nombre d’invocations, les taux d’erreur, la latence, les mesures d’utilisation et l’utilisation des tokens, ce qui permet aux SRE d’identifier et d'éliminer les goulots d’étranglement des performances, d’optimiser l’utilisation des ressources et d’assurer la maintenance de la fiabilité du système.
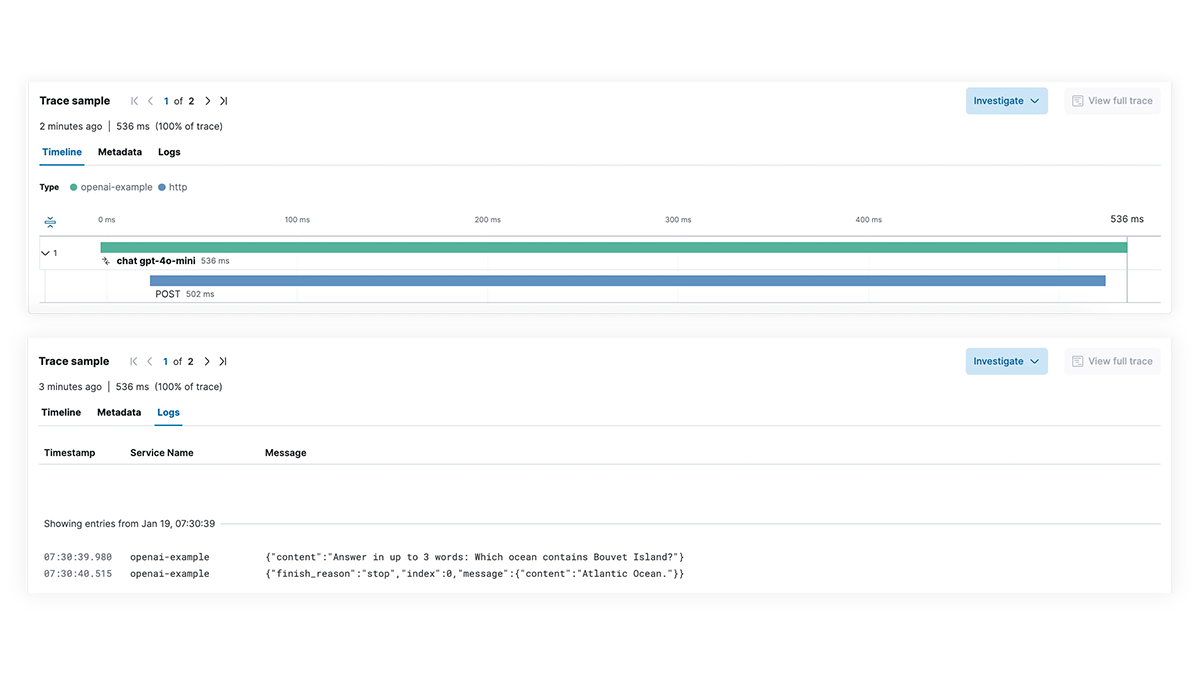
Ralentissement des performances ? Identifiez les causes profondes
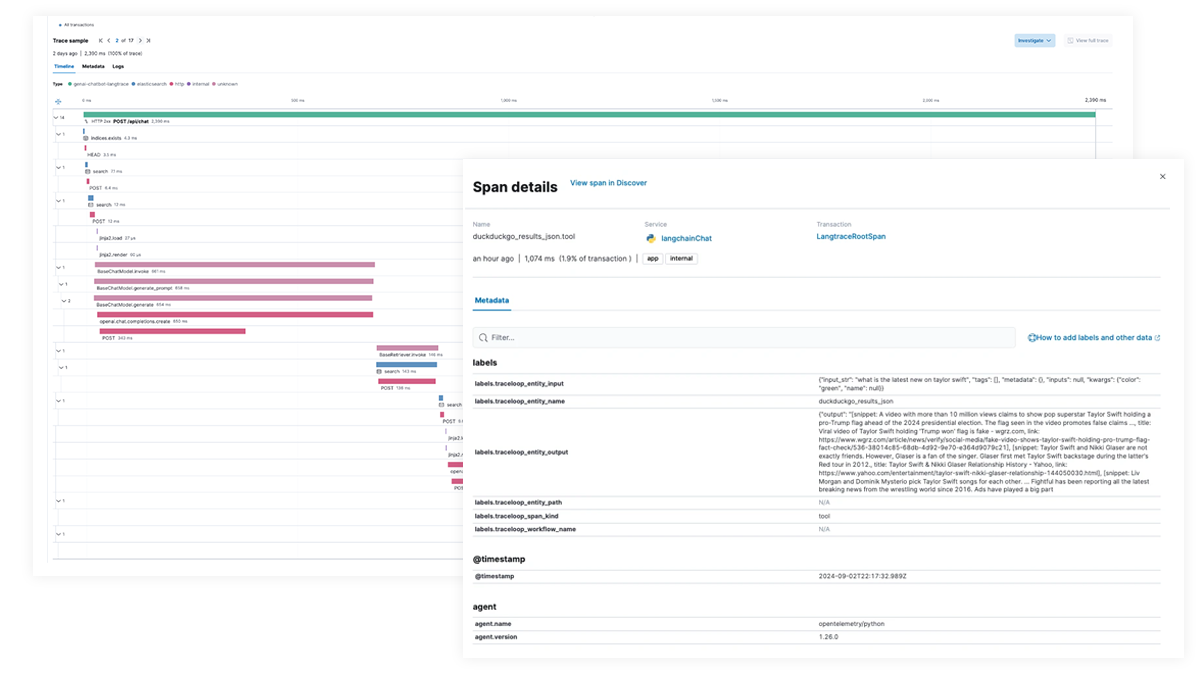
Bénéficiez d'une visibilité complète sur chaque étape du processus d'exécution du LLM pour les applications intégrant des fonctionnalités d'IA générative. Facilitez le débogage grâce au traçage de bout en bout, au mapping des dépendances des services et à la visibilité des requêtes LangChain, des appels LLM infructueux et des interactions avec les services externes. Résolvez rapidement les pannes et les pics de latence pour garantir des performances optimales.
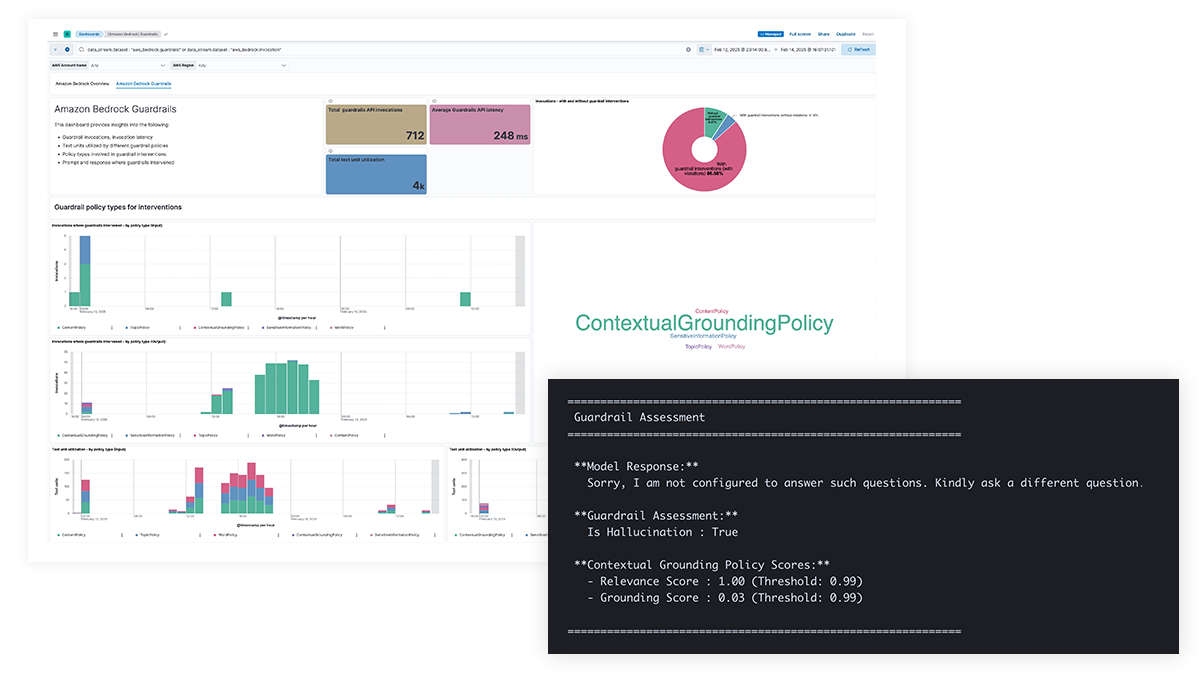
Des problèmes de sécurité liés à l’IA ? Obtenez une visibilité sur les invites et les réponses
Gagnez en transparence sur les invites et les réponses LLM pour vous protéger contre les fuites de données d’informations sensibles, de contenu nuisible ou indésirable et de problèmes éthiques, ainsi que pour traiter les erreurs factuelles, les biais et les hallucinations. La prise en charge d'Amazon Bedrock Guardrails et le filtrage de contenu pour Azure OpenAI permettent des interventions basées sur des politiques et fournissent des bases contextuelles pour améliorer la précision du modèle.
Des difficultés à suivre les coûts ? Voyez la répartition de l'utilisation par modèle
Les organisations ont besoin de visibilité sur l’utilisation des tokens, les appels d’API et les requêtes à coût élevé, les structures d'invite inefficaces et d’autres anomalies de coût pour optimiser les dépenses LLM. Elastic fournit des informations sur les modèles multimodaux, notamment le texte, la vidéo et les images, ce qui permet aux équipes de suivre et de gérer efficacement les coûts LLM.

Premiers pas avec l’observabilité LLM
ÉTAPE 2 : Tableaux de bord instantanés — disponibles immédiatement en quelques secondes
ÉTAPE 3 : Création d'alertes — transformez les données en actions
Visibilité pour les applications GenAI
Utilisez Elastic pour obtenir des informations de bout en bout sur les applications d'IA grâce à des bibliothèques de traçage tierces et à une visibilité prête à l'emploi sur les modèles hébergés par les principaux services LLM.












LLM observability dashboard gallery
The OpenAI integration for Elastic Observability includes prebuilt dashboards and metrics so you can effectively track and monitor OpenAI model usage, including GPT-4o and DALL·E.
Traçage de bout en bout avec EDOT et des bibliothèques tierces
Utilisez Elastic APM pour analyser et déboguer les applications LangChain avec OpenTelemetry. Cela peut être pris en charge par EDOT (Java, Python, Node.js) ou par des bibliothèques de traçage tierces telles que LangTrace, OpenLIT ou OpenLLMetry.
Essayez l’ application Elastic chatbot RAG. Cet exemple d’application combine Elasticsearch, LangChain et plusieurs LLM pour alimenter un chatbot avec ELSER et vos données privées.
Allez au-delà de l’observabilité LLM

APM

Suivi de l'expérience numérique

Analyse des logs

Suivi d'infrastructure

Elastic AI Assistant

Consolidation des outils

