Definición
¿Qué es la búsqueda de vectores?
La búsqueda de vectores aprovecha el machine learning (ML) para capturar el significado y el contexto de los datos no estructurados, incluido el texto y las imágenes, y transformarlos en una representación numérica. La búsqueda de vectores, que se usa con frecuencia para la búsqueda semántica, encuentra datos similares usando algoritmos de vecino más cercano aproximado (ANN). En comparación con la búsqueda de palabras clave tradicional, la búsqueda de vectores logra resultados más relevantes y se ejecuta más rápido.

¿Por qué es importante la búsqueda de vectores?
¿Qué tan seguido has buscado algo, pero no estás seguro de cómo se llama? Quizá sepas qué hace o tengas una descripción. Pero sin las palabras clave, solo te quedas buscando.
La búsqueda de vectores supera esta limitación, ya que te permite buscar por lo que quieres decir. Puede brindar rápidamente respuestas a consultas basadas en la búsqueda por similitud. Esto se debe a que la incrustación de vectores captura los datos no estructurados más allá del texto, como videos, imágenes y audio. Puedes mejorar la experiencia de búsqueda combinando la búsqueda de vectores con filtrado y agregaciones para optimizar la relevancia implementando una búsqueda híbrida y combinándola con la puntuación tradicional.
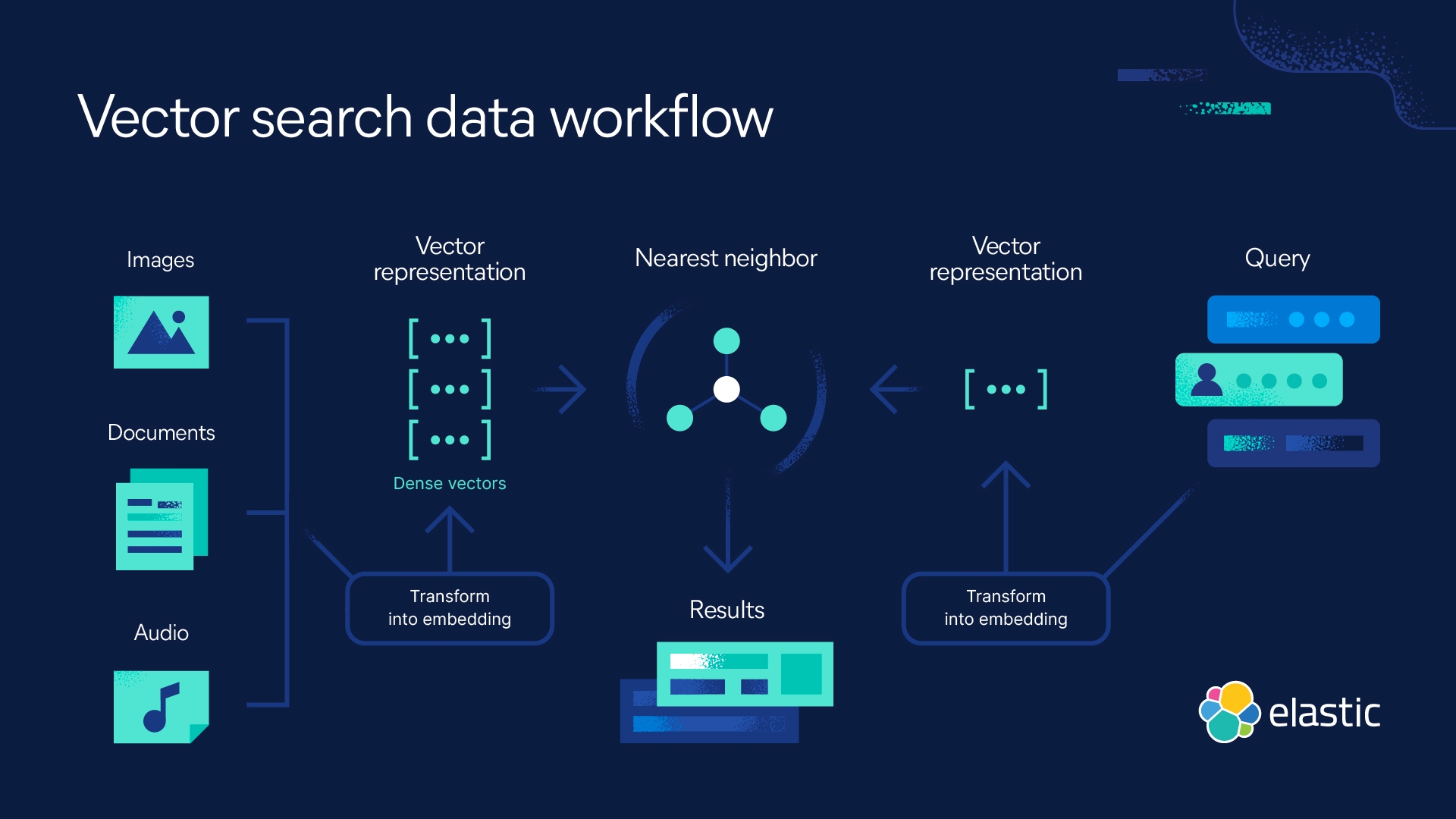
How does a vector search engine work?
Vector search engines — known as vector databases, semantic, or cosine search — find the nearest neighbors to a given (vectorized) query.
Where traditional search relies on mentions of keywords, lexical similarity, and the frequency of word occurrences, vector search engines use distances in the embedding space to represent similarity. Finding related data becomes searching for nearest neighbors of your query.
Casos de uso de búsqueda de vectores
La búsqueda de vectores no solo impulsa la próxima generación de experiencias de búsqueda, abre la puerta a una variedad de nuevas posibilidades.
Cómo dar los primeros pasos
Búsqueda de vectores y NLP simplificados con Elastic
No tienes que mover montañas para implementar la búsqueda de vectores y aplicar los modelos de NLP. Con Elasticsearch Relevance Engine™ (ESRE), obtienes un kit de herramientas para compilar aplicaciones de búsqueda de AI que se puedan usar con AI generativa y modelos de lenguaje grandes (LLM).
Con el ESRE, puedes compilar aplicaciones de búsqueda innovadoras, generar incrustaciones, almacenar vectores y buscar en ellos, e implementar la búsqueda semántica con Learned Sparse Encoder de Elastic. Conoce más sobre cómo usar Elasticsearch como tu base de datos de vectores.


