什么是混合搜索?
混合搜索的组件

混合搜索是关键字搜索、词汇搜索或 BM25(一种确定相关性的排名算法)与语义搜索的结合。语义搜索关注的是搜索所得到的结果,而向量搜索关注的是如何得到这些结果,主要是通过使用向量表示来检索数据。
语义搜索
语义搜索的核心在于理解意义和上下文。这种搜索侧重于理解查询词背后的意图,而不是像 BM25 搜索那样仅仅匹配关键字。语义搜索弥合了人类查询和实际含义之间的差距,解决了语言的多变性和模糊性问题。它利用自然语言处理 (NLP)、机器学习、知识图表和向量来提供与用户意图更相关并结合上下文的结果。
为了确定上下文,语义搜索可能会使用已知的用户数据、位置或过去的搜索历史来确定相关结果。在美国搜索“足球”与在世界其他地方搜索相同内容会得到不同结果。语义搜索根据用户的地理位置来区分意图。
向量搜索
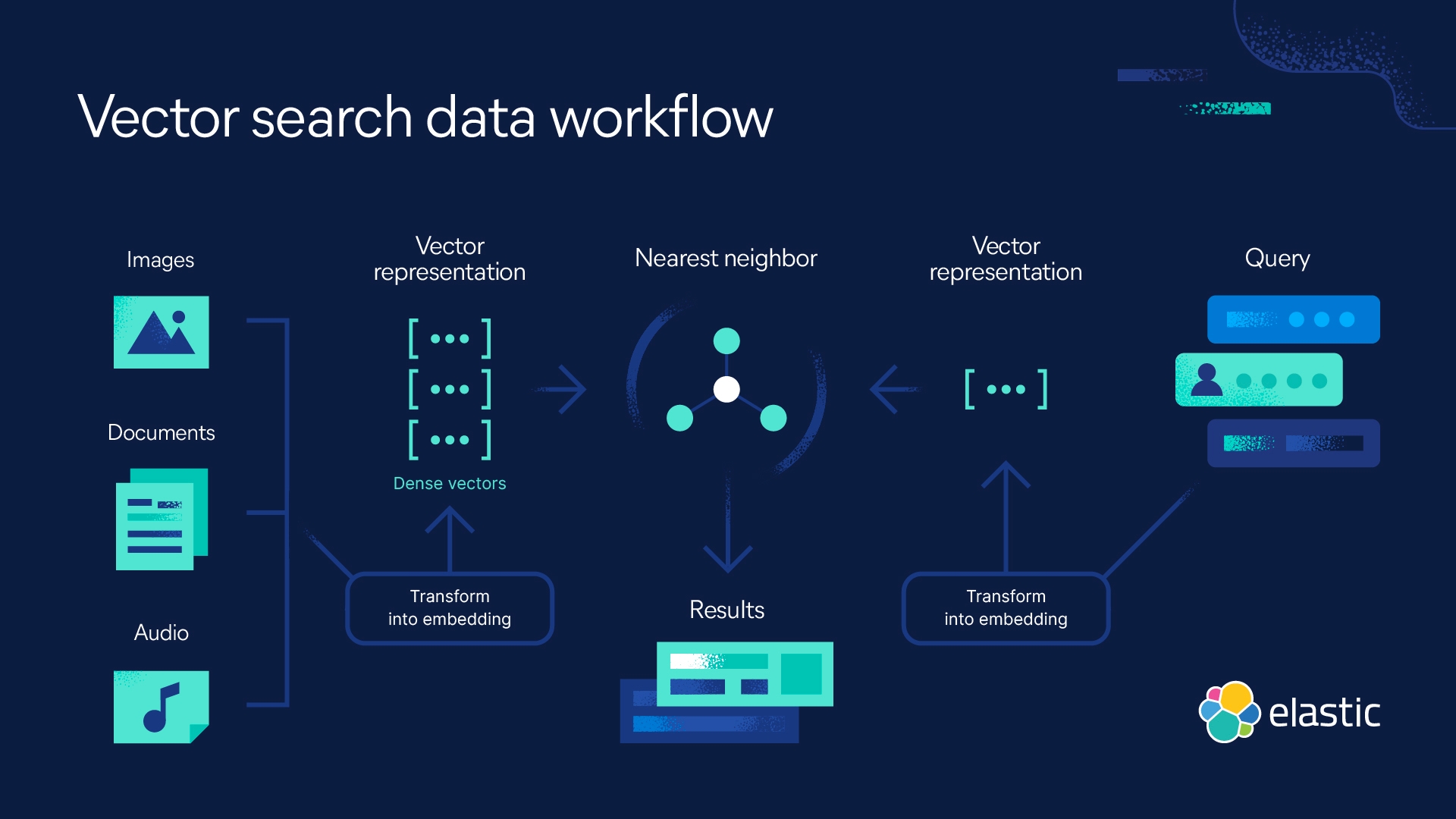
向量搜索是一种技术搜索方法,它使用数字表示或向量来表示文本、图像或音频等项目,并根据相似性检索数据。这些向量捕捉了这些项目的潜在含义或功能。向量搜索通过测量向量表示的相似性来检索数据。
结合多种方法
语义搜索和向量搜索有很多共同之处,事实上,语义搜索是由向量搜索提供支持的。
启动查询时,搜索引擎会将查询转换为向量嵌入。一种算法,如 kNN 算法(k 最近邻算法),将现有文档的向量与查询向量进行匹配。然后,算法根据概念相关性生成结果。
当语义搜索和向量搜索协同工作时,平台可以处理复杂的查询,包括多语言搜索和需要非结构化数据的搜索。
混合搜索的工作原理
混合搜索融合了关键字搜索和向量搜索,以提供全面的搜索结果。向量嵌入将数据(如句子或照片)转换为能捕捉其含义和关系的数字。数据被分词、索引并通过数字嵌入来表示。向量搜索可以捕获非结构化数据中的含义。矢量搜索克服了关键字搜索的局限性——允许用户按照他们的意图进行搜索,即使他们无法回忆起精确的描述或确切的关键字。混合搜索可以解析密集和稀疏向量,以获得最相关的结果。
密集向量
密集向量处理语义理解和上下文查询。它们通常用于现代机器学习,尤其是生成嵌入之类的任务。
稀疏向量
稀疏向量处理传统的基于关键字的索引,并且稀疏地填充信息。这些向量通常用于大型数据集。
查询处理
混合搜索中的查询处理使用稀疏向量进行精确的关键字匹配和优先级排序,并使用密集向量进行语义理解,捕捉上下文含义和意图。通过结合这两种类型的向量,混合搜索可以提供兼顾特异性和相关性的综合搜索结果。为了获得结果,混合搜索使用倒数排序融合 (RRF) 将多个结果集(每个结果集具有不同的相关性指标)组合成单个结果集。
混合搜索的优势
混合搜索通过利用不同搜索方法的综合优势,为用户带来了比传统搜索更多的益处。其主要优势是以更少的工作量提供更准确的搜索结果。
在各个行业中,内部和外部搜索算法都可以使用混合搜索来呈现相关结果。例如,电子商务平台能够区分“有口袋的红色连衣裙”和“在高档餐厅第一次约会时穿的红色连衣裙,口袋能装下钥匙和钱包”这样的搜索。
另一个例子是,在企业的内部福利文档中搜索“狗”可能会生成“办公室宠物政策”的结果。特定的词可能不会出现在查询中,但它可能是用户正在寻找的答案。
总体而言,混合搜索由于其语言灵活性而改善了用户搜索体验。混合搜索通过平衡语义理解和精确查询词来提高搜索精度。因此,对话式查询和复杂查询都能得到高效处理,避免陷入僵局和让用户感到沮丧。
使用 RAG 进行混合搜索
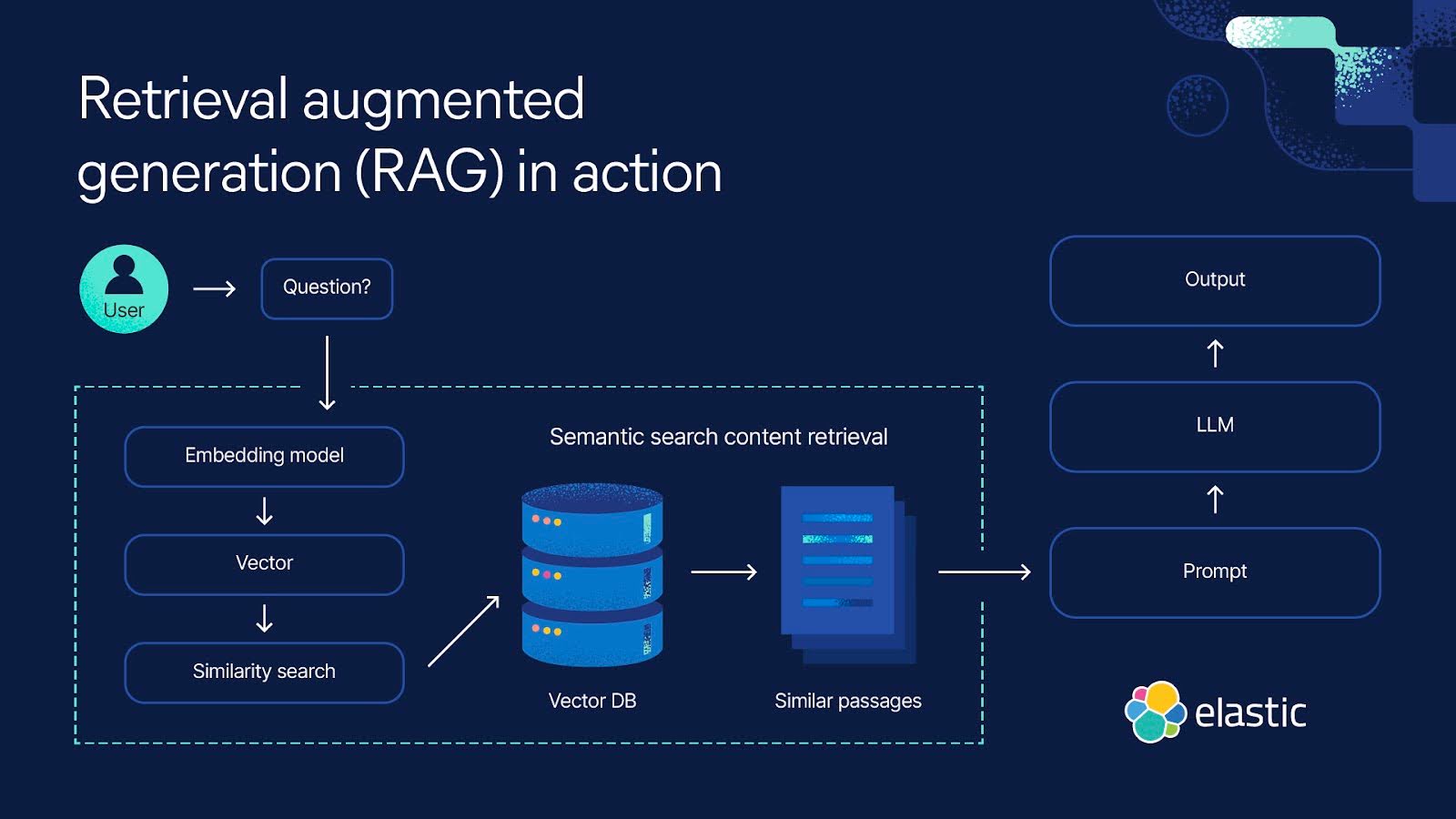
检索增强生成 (RAG) 是一种搜索技术,它使用私有或专有数据源来提供补充 LLM 的原始知识库的上下文。RAG 对于查询很有价值,因为它能使生成式 AI 系统能够使用外部信息源来生成更相关的响应。
将混合搜索与 RAG 结合使用,并引入其他数据源,可以通过添加上下文来提高搜索体验的相关性。附加信息源可以是组织或客户回答查询所需的任何内容,从互联网上的新信息到专有或机密的商业文档。
与单独工作的语言模型相比,RAG 具有多种优势。它具有成本效益,所需的计算和存储更少,并确保您的模型能够访问最新信息。
使用 Elastic 进行混合搜索
Elastic 通过支持开箱即用的语义搜索,轻松实现混合搜索。借助 Elastic,可以在一个平台、一个 API 上执行混合搜索,并且从一开始就具有更好的相关性、速度和扩展性。
借助 Elastic 的 Playground,开发人员可以在低代码接口中探索使用他们自己的私有数据来选择基础 LLM。
Elastic 通过新引入的查询检索器(标准、kNN 和 RRF)来帮助开发人员简化查询构造。使用这些查询,Elastic 会了解所选的数据并自动生成统一的查询。